![]()

Tutorial 3: Question Answering with Memory#
Week 2, Day 2: Neuro-Symbolic Methods
By Neuromatch Academy
Content creators: P. Michael Furlong, Chris Eliasmith
Content reviewers: Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy
Production editors: Konstantine Tsafatinos, Xaq Pitkow, Alex Murphy
Tutorial Objectives#
This model shows a form of question answering with memory. You will bind two features (color and shape) by circular convolution and store them in a memory population. Then you will provide a cue to the model at a later time to determine either one of the features by deconvolution. This model exhibits better cognitive ability since the answers to the questions are provided at a later time and not at the same time as the questions themselves. These operations use the primitives we introduced in Tutorial 1. Please make sure you have worked through previous tutorials so you can understand how operations such as circular convolution can implement binding of concepts.
Note: While we present a simplified interface using the Semantc Pointer Architecture, all the computations underlying the model you build are implemented using spiking neurons!
Setup (Colab Users: Please Read)#
Note that because this tutorial relies on some special Python packages, these packages have requirements for specific versions of common scientific libraries, such as numpy. If you’re in Google Colab, then as of May 2025, this comes with a later version (2.0.2) pre-installed. We require an older version (we’ll be installing 1.24.4). This causes Colab to force a session restart and then re-running of the installation cells for the new version to take effect. When you run the cell below, you will be prompted to restart the session. This is entirely expected and you haven’t done anything wrong. Simply click ‘Restart’ and then run the cells as normal.
An additional error might sometimes arise where an exception is raised connected to a missing element of NumPy. If this occurs, please restart the session and re-run the cells as normal and this error will go away. Updated versions of the affected libraries are expected out soon, but sadly not in time for the preparation of this material. We thank you for your understanding.
Install dependencies#
Show code cell source
# @title Install dependencies
!pip install numpy==1.24.4 --quiet
!pip install nengo nengo-spa nengo-gui --quiet
!pip install matplotlib vibecheck --quiet
Install and import feedback gadget#
Show code cell source
# @title Install and import feedback gadget
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_neuroai",
"user_key": "wb2cxze8",
},
).render()
feedback_prefix = "W2D2_T3"
Imports#
Show code cell source
# @title Imports
import matplotlib.pyplot as plt
import numpy as np
import logging
%matplotlib inline
import nengo
import nengo_spa as spa
seed = 0
Figure settings#
Show code cell source
# @title Figure settings
logging.getLogger('matplotlib.font_manager').disabled = True
%matplotlib inline
%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")
Intro#
Michael will give an introductory overview to the notion of performing question answering in the VSA setup we have been working with today.
Video 1: Introduction#
Nengo & Question Answering#
Nengo is a tool used to implement spiking and dynamic neural network systems. We will shortly introduce the basics of Nengo so you have a clear idea of how it works, what it can do and how we will be using it throughout this tutorial (and other tutorials) today. We’re then going to see how Nengo can be used on the application of Question Answering and then hand over to you to complete some interesting coding exercises to help you develop a feel for how to work with a basic example. These tools in your NeuroAI toolkit should then be a great start for you to continue learning about these methods and applying them to your your scientific questions and interests.
Video 2: Introduction to Nengo#
Section 1: Define the input functions#
The color input will RED and then BLUE for 0.25 seconds each before being turned off. In the same way the shape input will be CIRCLE and then SQUARE for 0.25 seconds each. Thus, the network will bind alternatingly RED * CIRCLE and BLUE * SQUARE for 0.5 seconds each.
The cue for deconvolving bound semantic pointers will be turned off for 0.5 seconds and then cycles through CIRCLE, RED, SQUARE, and BLUE within one second.
def color_input(t):
if t < 0.25:
return "RED"
elif t < 0.5:
return "BLUE"
else:
return "0"
def shape_input(t):
if t < 0.25:
return "CIRCLE"
elif t < 0.5:
return "SQUARE"
else:
return "0"
def cue_input(t):
if t < 0.5:
return "0"
sequence = ["0", "CIRCLE", "RED", "0", "SQUARE", "BLUE"]
idx = int(((t - 0.5) // (1.0 / len(sequence))) % len(sequence))
return sequence[idx]
Create the model#
Below we define a simple network compute the question answering. Note that the state labelled conv has the following arguments:
conv = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4)
feedback=1.0 determines the strength of a recurrent connection that provides memory. feedback_synapse=0.4 provides a time constant on a low-pass filter that models the synapses of the recurrent connection.
Transcode objects are modules provided by the Nengo programming framework to allow interaction with the outside world. They represent the interface between functions and the network, and execute simulus functions at runtime.
# Number of dimensions for the Semantic Pointers
dimensions = 32
model = spa.Network(label="Simple question answering", seed=seed)
with model:
color_in = spa.Transcode(color_input, output_vocab=dimensions)
shape_in = spa.Transcode(shape_input, output_vocab=dimensions)
bound = spa.State(dimensions, subdimensions=4, feedback=1.0, feedback_synapse=0.4) # conv
cue = spa.Transcode(cue_input, output_vocab=dimensions)
out = spa.State(dimensions)
# Connect the buffers
color_in * shape_in >> bound
bound * ~cue >> out
Probe the Model#
Next we are going to probe different parts of the model to record their state during operation. Probes are analogous to sensors used in performing electrophysiological experiments, and their readout acts like a low-pass filter, smoothing the activity through the synapse member. Here we specify the low pass filter to have a time constant of 0.03
We will create probes for all the components in the model: color_in, shape_in, cue, conv, and out. Specifically, we will probe the output member of each of these objects, as the Transcode and State objects represent more complex networks that are implemented in Nengo.
with model:
model.config[nengo.Probe].synapse = nengo.Lowpass(0.03)
p_color_in = nengo.Probe(color_in.output)
p_shape_in = nengo.Probe(shape_in.output)
p_cue = nengo.Probe(cue.output)
p_bound = nengo.Probe(bound.output)
p_out = nengo.Probe(out.output)
Video 3: Working Memory Functionality#
Run the model#
Now you will run the model using the programmatic Nengo interface. It will produce plots that compare similarity between different terms in our vocabulary (RED,BLUE,CIRCLE,SQUARE) and the states of the different elements of the networks.
Remember: when the module is representing a state in our vocabularity, the similarity should increase towards 1.
with nengo.Simulator(model) as sim:
sim.run(3.0)
Plot the results#
After we run the simulator, it will store the data from the probes we created earlier. Each of the probe objects above, say p_bound which records the output of the binding operation, bound, are keys for a dictionary of data stored in the simulator.
plt.figure(figsize=(10, 10))
vocab = model.vocabs[dimensions]
plt.subplot(5, 1, 1)
plt.plot(sim.trange(), spa.similarity(sim.data[p_color_in], vocab))
plt.legend(vocab.keys(), fontsize="x-small")
plt.ylabel("color")
plt.subplot(5, 1, 2)
plt.plot(sim.trange(), spa.similarity(sim.data[p_shape_in], vocab))
plt.legend(vocab.keys(), fontsize="x-small")
plt.ylabel("shape")
plt.subplot(5, 1, 3)
plt.plot(sim.trange(), spa.similarity(sim.data[p_cue], vocab))
plt.legend(vocab.keys(), fontsize="x-small")
plt.ylabel("cue")
plt.subplot(5, 1, 4)
for pointer in ["RED * CIRCLE", "BLUE * SQUARE"]:
plt.plot(sim.trange(), vocab.parse(pointer).dot(sim.data[p_bound].T), label=pointer)
plt.legend(fontsize="x-small")
plt.ylabel("Bound")
plt.subplot(5, 1, 5)
plt.plot(sim.trange(), spa.similarity(sim.data[p_out], vocab))
plt.legend(vocab.keys(), fontsize="x-small")
plt.ylabel("Output")
plt.xlabel("time [s]")
Text(0.5, 0, 'time [s]')
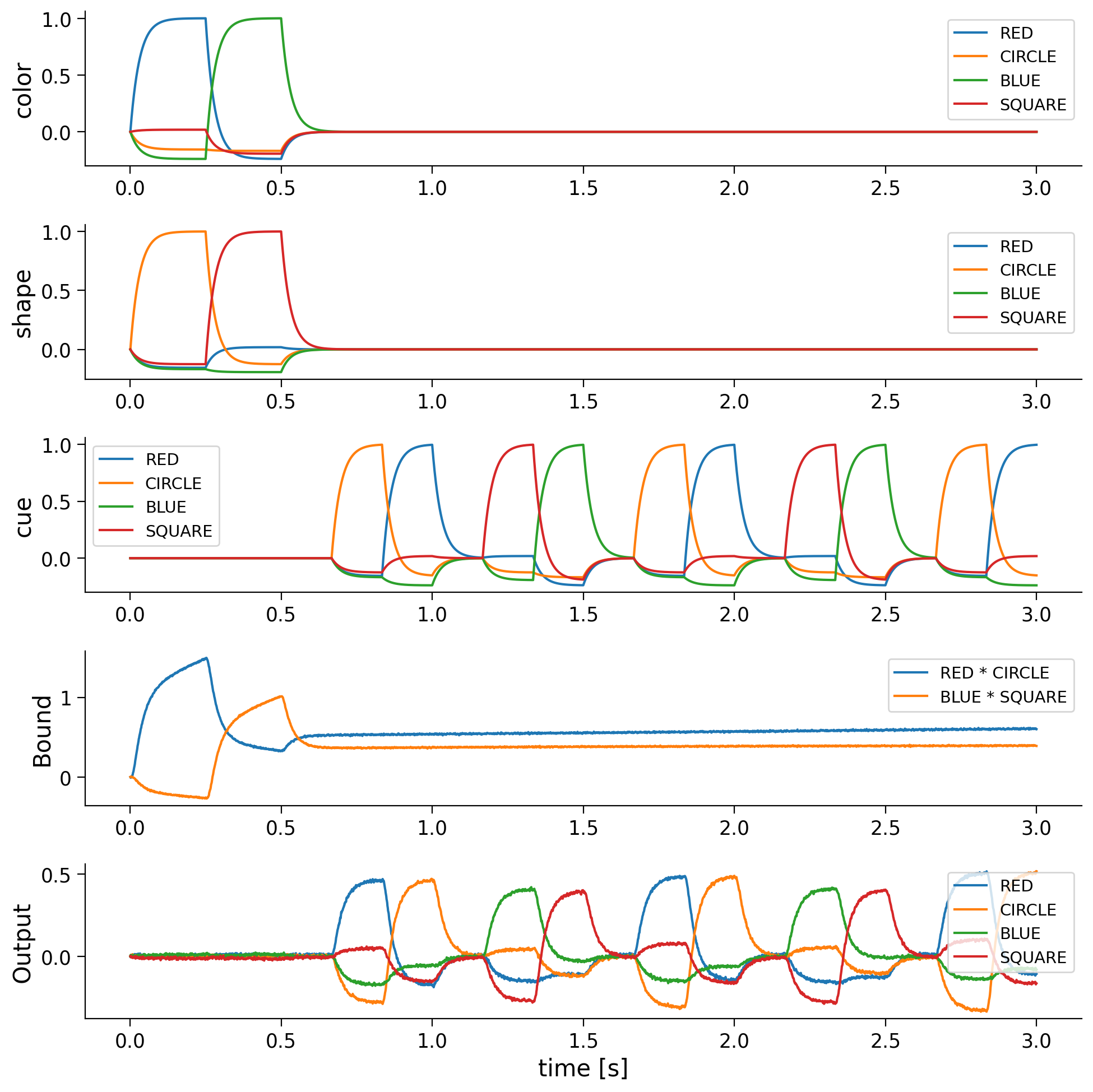
The plots of shape, color, and convolved show that first RED * CIRCLE and then BLUE * SQUARE will be loaded into the convolved buffer so after 0.5 seconds it represents the superposition RED * CIRCLE + BLUE * SQUARE.
The last plot shows that the output is most similar to the semantic pointer bound to the current cue. For example, when RED and CIRCLE are being convolved and the cue is CIRCLE, the output is most similar to RED. Thus, it is possible to unbind semantic pointers from the superposition stored in convolved.
You can see the effect of the memory unit in the model above because, even after the stimulus is turned off, the model is still able to answer the questions posed to it by the cue element.
You can also see the effect of the neural implementation in the noise in the output signal.
Video 4: Results Walthrough#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_results_walkthrough")
Coding Exercise#
QUESTION Try adding the concept of a GREEN * SQUARE to the model. Run the simulation for 5 seconds and compare the plots.
# Student code completion here
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_green_square_coding")
Video 5: Outro Video#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_outro")
The Big Picture#
You have now built a fairly simple cognitive model. A system that has an, albeit limited, vocabulary, expressed using a Vector Symbolic Algebra (VSA). Also, importantly, it is able to answer questions about it’s experience, even though the experience has passed, thanks to its working memory. Working memory is a vital component of cognitive models, and while this is a simple system, you have now experienced working with the tools that underly SPAUN, the world’s largest functional brain model.
Additionally, while you haven’t explicitly worked with them, this model was implemented completely with spiking neurons. The Neural Engineering Framework, the mathematical tools that underpin Nengo, allow us to compile the program we wrote using the VSA into a network of neurons. If you look closely at the plots above, you can see that the lines are noisy. This is because they are smoothed (thanks to the probes’ synapse) signals that represent the activity of the populations of neurons that implement our simple question answering model.
We have not one, but two extra bonus tutorials for today. These tutorials go into more depth on the basics around how to implement the notions of analogies in a VSA (Bonus Tutorial 4) and in Bonus Tutorial 5 we go through representations in continuous space. If you have any time left over, we encourage you to work your way through this extra material.