![]()

Tutorial 1: Task definition, application, relations and impacts on generalization#
Week 1, Day 2: Comparing Tasks
By Neuromatch Academy
Content creators: Deying Song, Leila Wehbe
Content reviewers: Samuele Bolotta, Hlib Solodzhuk, RyeongKyung Yoon, Lily Chamakura, Yizhou Chen, Ruiyi Zhang, Patrick Mineault, Alex Murphy
Production editors: Konstantine Tsafatinos, Ella Batty, Spiros Chavlis, Samuele Bolotta, Hlib Solodzhuk, Patrick Mineault, Alex Murphy
Tutorial Objectives#
Estimated timing of tutorial: 90 minutes
In this tutorial, we’ll explore how task specification affects generalization in networks. We will use the same base architecture (a convolutional neural network / CNN) to perform multiple different tasks. We will explore the number of training points and number of epochs needed to train these networks up to a specific accuracy value. Additionally, we will explore how well representations learned for a given task generalize, and whether these representations can be used to solve the other tasks.
Today’s learning objectives are:
Formulate different tasks in terms of cost functions
Train a network to accomplish these tasks and compare the performance of these networks
Measure how well different representations generalize
Let’s get started.
Setup#
Install and import feedback gadget#
Show code cell source
# @title Install and import feedback gadget
!pip install vibecheck numpy matplotlib torch torchvision tqdm ipywidgets memory-profiler requests scikit-learn torchmetrics --quiet
from vibecheck import DatatopsContentReviewContainer
def content_review(notebook_section: str):
return DatatopsContentReviewContainer(
"", # No text prompt
notebook_section,
{
"url": "https://pmyvdlilci.execute-api.us-east-1.amazonaws.com/klab",
"name": "neuromatch_neuroai",
"user_key": "wb2cxze8",
},
).render()
feedback_prefix = "W1D2_T1"
Import dependencies#
Show code cell source
# @title Import dependencies
# Import standard library dependencies
import os
import time
import gc
import logging
from pathlib import Path
import zipfile
import random
import contextlib
import io
# Import third-party libraries
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from tqdm.notebook import tqdm
from ipywidgets import Layout
from memory_profiler import profile
import requests
from sklearn.metrics import confusion_matrix
from torchmetrics import Accuracy
from torch.utils.data import DataLoader
import vibecheck
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, SubsetRandomSampler
from pathlib import Path
import time
from tqdm import tqdm
Figure settings#
Show code cell source
# @title Figure settings
logging.getLogger('matplotlib.font_manager').disabled = True
%matplotlib inline
%config InlineBackend.figure_format = 'retina' # perfrom high definition rendering for images and plots
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")
Set device (GPU or CPU)#
Show code cell source
# @title Set device (GPU or CPU)
def set_device():
"""
Determines and sets the computational device for PyTorch operations based on the availability of a CUDA-capable GPU.
Outputs:
- device (str): The device that PyTorch will use for computations ('cuda' or 'cpu'). This string can be directly used
in PyTorch operations to specify the device.
"""
device = "cuda" if torch.cuda.is_available() else "cpu"
if device != "cuda":
print("GPU is not enabled in this notebook. \n"
"If you want to enable it, in the menu under `Runtime` -> \n"
"`Hardware accelerator.` and select `GPU` from the dropdown menu")
else:
print("GPU is enabled in this notebook. \n"
"If you want to disable it, in the menu under `Runtime` -> \n"
"`Hardware accelerator.` and select `None` from the dropdown menu")
return device
device = set_device()
GPU is not enabled in this notebook.
If you want to enable it, in the menu under `Runtime` ->
`Hardware accelerator.` and select `GPU` from the dropdown menu
Helper functions#
Show code cell source
# @title Helper functions
class BottleneckLayer(nn.Module):
def __init__(self, M):
super(BottleneckLayer, self).__init__()
self.fc = nn.Linear(LATENT_DIM, M)
def forward(self, x):
x = F.relu(self.fc(x))
return x
class ConvNeuralNetDecoder(nn.Module):
def __init__(self, M):
super(ConvNeuralNetDecoder, self).__init__()
self.fc3 = nn.Linear(M, LATENT_DIM)
self.fc2 = nn.Linear(84, 120)
self.fc1 = nn.Linear(120, 16 * 5 * 5)
self.convT2 = nn.ConvTranspose2d(16, 6, 5, stride=2, padding=0, output_padding=1)
self.convT1 = nn.ConvTranspose2d(6, 1, 5, stride=2, padding=0, output_padding=1)
def forward(self, x):
x = F.relu(self.fc3(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc1(x))
x = x.view(-1, 16, 5, 5)
x = F.relu(self.convT2(x))
x = self.convT1(x)
return x
def get_random_sample_dataloader(dataset, batch_size, M):
indices = torch.randperm(len(dataset))[:M]
sampler = SubsetRandomSampler(indices)
sampled_loader = DataLoader(dataset, batch_size=batch_size, sampler=sampler, pin_memory=True)
return sampled_loader
def get_random_sample_train_val(train_dataset, val_dataset, batch_size, N_train_data):
sampled_train_loader = get_random_sample_dataloader(train_dataset, batch_size, N_train_data)
N_val_data = int(N_train_data / 9.0)
if N_val_data < 30:
N_val_data = 30
sampled_val_loader = get_random_sample_dataloader(val_dataset, batch_size, N_val_data)
return sampled_train_loader, sampled_val_loader
class Accuracy:
def __init__(self, task='multiclass', num_classes=10):
assert task == 'multiclass', "Only supports `multiclass` task accuracy!"
self.num_classes = num_classes
def __call__(self, predicted, target):
correct = predicted.eq(target.view_as(predicted)).sum().item()
return correct / predicted.size(0)
def save_model(model, task_name, N_train_data, epoch, train_loss, val_loss):
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
MODEL_NAME = f"ConvNet_{task_name}_{N_train_data}_epoch_{epoch}.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
print(f"Saving the model: {MODEL_SAVE_PATH}")
checkpoint = {
'model_state_dict': model.state_dict(),
'train_loss': train_loss,
'val_loss': val_loss
}
torch.save(obj=checkpoint, f=MODEL_SAVE_PATH)
def train(model, train_dataloader, val_dataloader, test_dataloader, cost_fn, optimizer, epochs_max, acc_flag, triplet_flag, task_name, N_train_data):
tstart = time.time()
accuracy = Accuracy(task='multiclass', num_classes=10)
epoch = 0
val_cost_last = 100000.0
val_cost_current = 100000.0
my_epoch = []
my_train_cost = []
my_test_cost = []
train_losses = []
val_losses = []
model = model.to(device)
if triplet_flag:
for epoch in tqdm(range(1, epochs_max + 1), desc="Training epochs", unit="epoch"):
my_epoch.append(epoch)
train_cost = 0.0
for batch_idx, (anchor_img, positive_img, negative_img) in enumerate(train_dataloader):
model.train()
anchor_img, positive_img, negative_img = anchor_img.cuda(), positive_img.cuda(), negative_img.cuda()
anchor_reconstruct = model(anchor_img)
positive_reconstruct = model(positive_img)
negative_reconstruct = model(negative_img)
cost = cost_fn(anchor_reconstruct, positive_reconstruct, negative_reconstruct)
train_cost += cost.item()
optimizer.zero_grad()
cost.backward()
optimizer.step()
train_cost /= len(train_dataloader)
train_losses.append(train_cost)
my_train_cost.append(train_cost)
val_cost = 0.0
model.eval()
with torch.no_grad():
for batch_idx, (anchor_img, positive_img, negative_img) in enumerate(val_dataloader):
anchor_img, positive_img, negative_img = anchor_img.cuda(), positive_img.cuda(), negative_img.cuda()
anchor_reconstruct = model(anchor_img)
positive_reconstruct = model(positive_img)
negative_reconstruct = model(negative_img)
cost = cost_fn(anchor_reconstruct, positive_reconstruct, negative_reconstruct)
val_cost += cost.item()
val_cost /= len(val_dataloader)
val_cost_last = val_cost_current
val_cost_current = val_cost
val_losses.append(val_cost)
test_cost = 0.0
model.eval()
with torch.no_grad():
for batch_idx, (anchor_img, positive_img, negative_img) in enumerate(test_dataloader):
anchor_img, positive_img, negative_img = anchor_img.cuda(), positive_img.cuda(), negative_img.cuda()
anchor_reconstruct = model(anchor_img)
positive_reconstruct = model(positive_img)
negative_reconstruct = model(negative_img)
cost = cost_fn(anchor_reconstruct, positive_reconstruct, negative_reconstruct)
test_cost += cost.item()
test_cost /= len(test_dataloader)
my_test_cost.append(test_cost)
print(f"Epoch: {epoch}| Train cost: {train_cost: .5f}| " +
f"Val cost: {val_cost: .5f}| " +
f"Test cost: {test_cost: .5f}|")
save_model(model, task_name, N_train_data, epoch, train_cost, val_cost)
else:
for epoch in tqdm(range(1, epochs_max + 1), desc="Training epochs", unit="epoch"):
my_epoch.append(epoch)
train_cost, train_acc = 0.0, 0.0
for batch_idx, (X, y) in enumerate(train_dataloader):
model.train()
X = X.to(device)
y = y.to(device)
predictions = model(X)
cost = cost_fn(predictions, y)
train_cost += cost.item()
if acc_flag:
_, predicted_classes = torch.max(predictions, 1)
acc = accuracy(predicted_classes, y)
train_acc += acc
optimizer.zero_grad()
cost.backward()
optimizer.step()
train_cost /= len(train_dataloader)
if acc_flag:
train_acc /= len(train_dataloader)
train_losses.append(train_cost)
my_train_cost.append(train_cost)
val_cost, val_acc = 0.0, 0.0
model.eval()
with torch.no_grad():
for batch_idx, (X, y) in enumerate(val_dataloader):
X = X.to(device)
y = y.to(device)
predictions = model(X)
cost = cost_fn(predictions, y)
val_cost += cost.item()
if acc_flag:
_, predicted_classes = torch.max(predictions, 1)
acc = accuracy(predicted_classes, y)
val_acc += acc
val_cost /= len(val_dataloader)
val_cost_last = val_cost_current
val_cost_current = val_cost
if acc_flag:
val_acc /= len(val_dataloader)
val_losses.append(val_cost)
test_cost, test_acc = 0.0, 0.0
model.eval()
with torch.no_grad():
for batch_idx, (X, y) in enumerate(test_dataloader):
X = X.to(device)
y = y.to(device)
predictions = model(X)
cost = cost_fn(predictions, y)
test_cost += cost.item()
if acc_flag:
_, predicted_classes = torch.max(predictions, 1)
acc = accuracy(predicted_classes, y)
test_acc += acc
test_cost /= len(test_dataloader)
my_test_cost.append(test_cost)
if acc_flag:
test_acc /= len(test_dataloader)
if acc_flag:
print(f"Epoch: {epoch}| Train cost: {train_cost: .5f}| Train acc: {train_acc: .5f}| " +
f"Val cost: {val_cost: .5f}| Val acc: {val_acc: .5f}| " +
f"Test cost: {test_cost: .5f}| Test acc: {test_acc: .5f}")
else:
print(f"Epoch: {epoch}| Train cost: {train_cost: .5f}| " +
f"Val cost: {val_cost: .5f}| " +
f"Test cost: {test_cost: .5f}|")
save_model(model, task_name, N_train_data, epoch, train_cost, val_cost)
elapsed = time.time() - tstart
print('Elapsed: %s' % elapsed)
loss_data = {'train_losses': train_losses, 'val_losses': val_losses}
torch.save(loss_data, 'loss_data.pth')
return my_epoch, my_train_cost, val_losses, my_test_cost
def train_transfer(model, train_dataloader, val_dataloader, test_dataloader, cost_fn, optimizer, epochs_max, acc_flag, triplet_flag, task_name, N_train_data):
tstart = time.time()
accuracy = Accuracy(task='multiclass', num_classes=10)
epoch = 0
val_cost_last = 100000.0
val_cost_current = 100000.0
my_epoch = []
my_train_cost = []
my_test_cost = []
train_losses = []
val_losses = []
model = model.to(device)
if triplet_flag:
for epoch in tqdm(range(1, epochs_max + 1), desc="Training epochs", unit="epoch"):
my_epoch.append(epoch)
train_cost = 0.0
for batch_idx, (anchor_img, positive_img, negative_img) in enumerate(train_dataloader):
model.train()
anchor_img, positive_img, negative_img = anchor_img.cuda(), positive_img.cuda(), negative_img.cuda()
anchor_reconstruct = model(anchor_img)
positive_reconstruct = model(positive_img)
negative_reconstruct = model(negative_img)
cost = cost_fn(anchor_reconstruct, positive_reconstruct, negative_reconstruct)
train_cost += cost.item()
optimizer.zero_grad()
cost.backward()
optimizer.step()
train_cost /= len(train_dataloader)
train_losses.append(train_cost)
my_train_cost.append(train_cost)
val_cost = 0.0
model.eval()
with torch.no_grad():
for batch_idx, (anchor_img, positive_img, negative_img) in enumerate(val_dataloader):
anchor_img, positive_img, negative_img = anchor_img.cuda(), positive_img.cuda(), negative_img.cuda()
anchor_reconstruct = model(anchor_img)
positive_reconstruct = model(positive_img)
negative_reconstruct = model(negative_img)
cost = cost_fn(anchor_reconstruct, positive_reconstruct, negative_reconstruct)
val_cost += cost.item()
val_cost /= len(val_dataloader)
val_cost_last = val_cost_current
val_cost_current = val_cost
val_losses.append(val_cost)
test_cost = 0.0
model.eval()
with torch.no_grad():
for batch_idx, (anchor_img, positive_img, negative_img) in enumerate(test_dataloader):
anchor_img, positive_img, negative_img = anchor_img.cuda(), positive_img.cuda(), negative_img.cuda()
anchor_reconstruct = model(anchor_img)
positive_reconstruct = model(positive_img)
negative_reconstruct = model(negative_img)
cost = cost_fn(anchor_reconstruct, positive_reconstruct, negative_reconstruct)
test_cost += cost.item()
test_cost /= len(test_dataloader)
my_test_cost.append(test_cost)
print(f"Epoch: {epoch}| Train cost: {train_cost: .5f}| " +
f"Val cost: {val_cost: .5f}| " +
f"Test cost: {test_cost: .5f}|")
save_model(model, task_name, N_train_data, epoch, train_cost, val_cost)
else:
for epoch in tqdm(range(1, epochs_max + 1), desc="Training epochs", unit="epoch"):
my_epoch.append(epoch)
train_cost, train_acc = 0.0, 0.0
for batch_idx, (X, y) in enumerate(train_dataloader):
model.train()
X = X.to(device)
y = y.to(device)
predictions = model(X)
cost = cost_fn(predictions, y)
train_cost += cost.item()
if acc_flag:
_, predicted_classes = torch.max(predictions, 1)
acc = accuracy(predicted_classes, y)
train_acc += acc
optimizer.zero_grad()
cost.backward()
optimizer.step()
train_cost /= len(train_dataloader)
if acc_flag:
train_acc /= len(train_dataloader)
train_losses.append(train_cost)
my_train_cost.append(train_cost)
val_cost, val_acc = 0.0, 0.0
model.eval()
with torch.no_grad():
for batch_idx, (X, y) in enumerate(val_dataloader):
X = X.to(device)
y = y.to(device)
predictions = model(X)
cost = cost_fn(predictions, y)
val_cost += cost.item()
if acc_flag:
_, predicted_classes = torch.max(predictions, 1)
acc = accuracy(predicted_classes, y)
val_acc += acc
val_cost /= len(val_dataloader)
val_cost_last = val_cost_current
val_cost_current = val_cost
if acc_flag:
val_acc /= len(val_dataloader)
val_losses.append(val_cost)
test_cost, test_acc = 0.0, 0.0
model.eval()
with torch.no_grad():
for batch_idx, (X, y) in enumerate(test_dataloader):
X = X.to(device)
y = y.to(device)
predictions = model(X)
cost = cost_fn(predictions, y)
test_cost += cost.item()
if acc_flag:
_, predicted_classes = torch.max(predictions, 1)
acc = accuracy(predicted_classes, y)
test_acc += acc
test_cost /= len(test_dataloader)
my_test_cost.append(test_cost)
if acc_flag:
test_acc /= len(test_dataloader)
if acc_flag:
print(f"Epoch: {epoch}| Train cost: {train_cost: .5f}| Train acc: {train_acc: .5f}| " +
f"Val cost: {val_cost: .5f}| Val acc: {val_acc: .5f}| " +
f"Test cost: {test_cost: .5f}| Test acc: {test_acc: .5f}")
else:
print(f"Epoch: {epoch}| Train cost: {train_cost: .5f}| " +
f"Val cost: {val_cost: .5f}| " +
f"Test cost: {test_cost: .5f}|")
save_model(model, task_name, N_train_data, epoch, train_cost, val_cost)
elapsed = time.time() - tstart
print('Elapsed: %s' % elapsed)
loss_data = {'train_losses': train_losses, 'val_losses': val_losses}
torch.save(loss_data, 'loss_data.pth')
return my_epoch, my_train_cost, val_losses, my_test_cost
Plotting functions#
Show code cell source
# @title Plotting functions
def plot_reconstructions(original_images, reconstructed_images, N_train_data, epochs):
fig = plt.figure(figsize=(10, 5))
rows, cols = 2, 6
image_count = 0
for i in range(1, rows * cols, 2):
fig.add_subplot(rows, cols, i)
plt.imshow(np.squeeze(original_images[image_count]), cmap='gray')
plt.title(f"Original {image_count+1}", fontsize=8)
plt.axis('off')
fig.add_subplot(rows, cols, i + 1)
plt.imshow(np.squeeze(reconstructed_images[image_count]), cmap='gray')
plt.title(f"Reconstructed {image_count+1}", fontsize=8)
plt.axis('off')
image_count += 1
fig.suptitle(f"Training for {epochs} epochs with {N_train_data} points")
plt.show()
def cost_classification(output, target):
criterion = nn.CrossEntropyLoss()
target = target.to(torch.int64)
cost = criterion(output, target)
return cost
def cost_regression(output, target):
criterion = nn.MSELoss()
cost = criterion(output, target)
return cost
def cost_autoencoder(output, target):
criterion = nn.MSELoss()
output_flat = output.view(output.size(0), -1)
target_flat = target.view(target.size(0), -1)
cost = criterion(output_flat, target_flat)
return cost
Data retrieval#
Show code cell source
# @title Data retrieval
import os
import requests
import hashlib
import zipfile
def download_file(fname, url, expected_md5):
"""
Downloads a file from the given URL and saves it locally.
"""
if not os.path.isfile(fname):
try:
r = requests.get(url)
except requests.ConnectionError:
print("!!! Failed to download data !!!")
return
if r.status_code != requests.codes.ok:
print("!!! Failed to download data !!!")
return
if hashlib.md5(r.content).hexdigest() != expected_md5:
print("!!! Data download appears corrupted !!!")
return
with open(fname, "wb") as fid:
fid.write(r.content)
def extract_zip(zip_fname):
"""
Extracts a ZIP file to the current directory.
"""
with zipfile.ZipFile(zip_fname, 'r') as zip_ref:
zip_ref.extractall(".")
# Details for the zip files to be downloaded and extracted
zip_files = [
{
"fname": "models.zip",
"url": "https://osf.io/dms2n/download",
"expected_md5": "2c88be8804ae546da6c6985226bc98e7"
}
]
# Process zip files: download and extract
for zip_file in zip_files:
download_file(zip_file["fname"], zip_file["url"], zip_file["expected_md5"])
extract_zip(zip_file["fname"])
Set random seed#
Show code cell source
# @title Set random seed
def set_seed(seed=None, seed_torch=True):
if seed is None:
seed = np.random.choice(2 ** 32)
random.seed(seed)
np.random.seed(seed)
if seed_torch:
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
set_seed(seed = 42)
Section 1: Tasks as Cost Functions#
We formalize different tasks as cost functions and train the same base architecture on the same dataset. Check out the video below to learn more about how we will do this!
Tutorial Video#
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Tutorial_Video")
Review of CNNs#
In this tutorial, we will use a simple Convolutional Neural Network (CNN) architecture and a subset of the MNIST dataset, which consists of images of handwritten digits (See the Intro video for more information on MNIST). We will use the same base architecture and training dataset to accomplish different tasks by creating various output layers (heads) and train them with different cost functions, thereby specifying different tasks to be completed. With different cost functions, the networks are forced to pay attention to different things as their end goal has changed and it’s this property that changes what the network tries to do.
A Convolutional Neural Network (CNN) is a deep learning algorithm designed to process input images, assign importance (learnable weights and biases) to various features within the images, and distinguish between different objects. Unlike pure feedforward neural networks that flatten the input into a one-dimensional array, CNNs preserve the spatial structure of the input images. This makes them particularly effective for processing data with a grid-like structure, such as images. A CNN architecture is engineered to automatically and adaptively learn spatial hierarchies of features, ranging from low-level (basic) to high-level (complex) patterns.
The core components of CNNs are convolutional layers, pooling layers, and fully connected layers. A schematic of a CNN is shown below.
Convolutional layers apply convolution operations to the input and pass the results to the next layer. This enables the network to be deep with fewer parameters, enhancing the learning of feature hierarchies.
Pooling layers reduce the dimensions of the data by combining the outputs of neuron clusters at one layer into a single neuron in the next layer.
Fully connected layers connect every neuron in one layer to every neuron in the next layer and are typically used at the end of the network to make class predictions.
Due to their ability to capture the spatial (image) and temporal (video) dependencies through the application of relevant filters, CNNs are extensively used in image and video recognition, recommender systems, image classification, medical image analysis, and natural language processing.

The first CNNs were devised in the late 1980s by Yann LeCun and they were designed to solve the digit recognition task present in the MNIST dataset. It’s a simple yet effective architecture that demonstrates the main concepts that still underly many more advanced CNN architectures today. Here we’ll replicate the structure of LeNet up to the fully connected fc2 layer. The latent representation in this layer is 84 dimensional. We’ll add various decoder heads and bottleneck layers to this core architecture (sometimes called a backbone) and then we will train on different objectives (cost functions), and we will see how the representations change.
LATENT_DIM = 84
class ConvNeuralNet(nn.Module):
def __init__(self):
super(ConvNeuralNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, LATENT_DIM)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return x
Preparing the data#
with contextlib.redirect_stdout(io.StringIO()):
# Define a transformation pipeline for the MNIST dataset
mnist_transform = transforms.Compose([
transforms.Resize((32, 32)), # Resize the images to 32x32 pixels
transforms.ToTensor(), # Convert images to PyTorch tensors
transforms.Normalize(mean=(0.1307,), std=(0.3081,)) # Normalize the images with mean and standard deviation
])
# Load the MNIST training dataset with transformations applied
train_val_dataset = torchvision.datasets.MNIST(
root='./data', # Directory to store/load the data
train=True, # Specify to load the training set
transform=mnist_transform, # Apply the transformation pipeline defined earlier
download=True # Download the dataset if it's not already present
)
# Load the MNIST test dataset with transformations applied
test_dataset = torchvision.datasets.MNIST(
root='./data', # Directory to store/load the data
train=False, # Specify to load the test set
transform=mnist_transform, # Apply the transformation pipeline defined earlier
download=True # Download the dataset if it's not already present
)
# Split the training dataset into training and validation sets
train_size = int(0.9 * len(train_val_dataset)) # Calculate the size of the training set (90% of the original)
val_size = len(train_val_dataset) - train_size # Calculate the size of the validation set (remaining 10%)
train_dataset, val_dataset = torch.utils.data.random_split(
dataset=train_val_dataset, # Original training dataset to split
lengths=[train_size, val_size] # Lengths of the resulting splits
)
# Split the test dataset into two halves: original and transfer sets
test_size_original = int(0.5 * len(test_dataset)) # Calculate the size of the original test set (50% of the original)
test_size_transfer = len(test_dataset) - test_size_original # Calculate the size of the transfer test set (remaining 50%)
test_dataset_original, test_dataset_transfer = torch.utils.data.random_split(
dataset=test_dataset, # Original test dataset to split
lengths=[test_size_original, test_size_transfer] # Lengths of the resulting splits
)
# Display the training dataset object
train_dataset
Visualizing some samples from the dataset#
# Retrieve the class names (labels) from the training dataset
class_names = train_dataset.dataset.classes
# Set a manual seed for PyTorch to ensure reproducibility of results
torch.manual_seed(10)
# Create a figure for displaying the images
fig = plt.figure(figsize=(8, 4)) # Set the figure size to 8x4 inches
rows, cols = 2, 5 # Define the number of rows and columns for the subplot grid
# Define the mean and standard deviation used for normalization
mean = 0.1307
std = 0.3081
# Loop to display a grid of sample images from the training dataset
for i in range(1, (rows*cols) + 1):
rand_ind = torch.randint(0, len(train_dataset), size=[1]).item()
img, label = train_dataset[rand_ind]
img_tensor = img * std + mean
img_tensor = img_tensor / 2 + 0.5
img_np = np.squeeze(img_tensor.numpy())
fig.add_subplot(rows, cols, i)
plt.imshow(img_np, cmap='gray')
plt.title(f"{class_names[label]}")
plt.axis(False)
plt.tight_layout()

Preparing the data loaders#
batch_size = 32
# Create a DataLoader for the training dataset
train_loader = DataLoader(
dataset=train_dataset, # The dataset to load data from
batch_size=batch_size, # The number of samples per batch
shuffle=True # Shuffle the data at every epoch
)
# Create a DataLoader for the validation dataset
val_loader = DataLoader(
dataset=val_dataset, # The dataset to load data from
batch_size=batch_size, # The number of samples per batch
shuffle=True # Shuffle the data at every epoch
)
# Create a DataLoader for the original test dataset
test_loader_original = DataLoader(
dataset=test_dataset_original, # The dataset to load data from
batch_size=batch_size, # The number of samples per batch
shuffle=True # Shuffle the data at every epoch
)
# Create a DataLoader for the transfer test dataset
test_loader_transfer = DataLoader(
dataset=test_dataset_transfer, # The dataset to load data from
batch_size=batch_size, # The number of samples per batch
shuffle=True # Shuffle the data at every epoch
)
# Defining epochs and batch size
epochs_max = 20
batch_size = 32
Section 1.1: Classification#
In this task, we’ll train the CNN to classify digits into one of 10 different classes.
Code exercise 1: Cost Function#
Training#
In this task, we aim to classify hand-written digits from images, where each digit ranges from 0 to 9. To achieve this, we add a classification head to the CNN.
We introduce an output layer Y with 10 nodes, each representing one of the possible digits. The output layer uses the softmax activation function to produce probability scores for each class:
where \(\mu_j = \text{CNN}_j(x)\) is the output of the \(j^{th}\) node in the output layer.
class ClassificationOutputLayer(nn.Module):
def __init__(self):
super(ClassificationOutputLayer, self).__init__()
self.fc = nn.Linear(LATENT_DIM, 10)
def forward(self, x):
x = F.softmax(self.fc(x), dim=1)
return x
Thus, the network outputs a probability distribution over the 10 possible classes for each input image.
Cost Function#
To train the network effectively, we implement a cost function based the the concept of cross-entropy. The cost function is defined as:
where:
\(N\) is the number of samples
\(y_{ij}\) is the true label for the \(i^{th}\) sample, encoded as a one-hot vector
\(p(y_{ij}|x_i)\) is the predicted probability of the \(j^{th}\) class for the \(i^{th}\) sample.
############################################################
raise NotImplementedError("Student exercise: Calculate the loss using the criterion")
############################################################
def cost_classification(output, target):
criterion = nn.CrossEntropyLoss()
target = target.to(torch.int64)
cost = ...
return cost
By implementing this cost function, the model is trained to minimize the difference between the predicted probability distributions and the actual one-hot encoded targets (also a probability distribution, but with all of the weight on a single class).
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Cost_Function")
Defining the model#
We define a CNN model with a classification head to classify the digits.
class ClassificationConvNet(nn.Module):
def __init__(self, ConvNet, Output):
super(ClassificationConvNet, self).__init__()
self.ConvNet = ConvNet
self.Output = Output
def forward(self, x):
conv_intermediate = self.ConvNet(x)
output = self.Output(conv_intermediate)
return output
Here, ConvNet represents the convolutional part of the network responsible for feature extraction, while Output is the classification output layer described earlier and implemented in code. In the slot for ConvNet, we will be passing the instantiated object ConvNeuralNet (see above) and in the slot for Output, we will be passing the instantiated object ClassificationOutputLayer (also defined above).
Training on different dataset sizes#
We conduct training experiments with this model on varying dataset sizes (10, 100, 1000, 10000). This approach helps us understand how the model’s performance scales with the amount of training data available (sample complexity). Larger datasets typically improve the model’s ability to generalize to the test set.
set_seed(42)
# Usage example for classification task
training_points = np.array([10, 100, 1000, 10000])
task_name_classification = "classification"
acc_flag_classification = True
triplet_flag_classification = False
epochs_max_classification = 10
my_epoch_Classification = []
my_train_cost_Classification = [] # Add a list to store training costs
my_val_cost_Classification = [] # Add a list to store val costs
my_test_cost_Classification = [] # Add a list to store test costs
conf_matrices = [] # List to store confusion matrices
for N_train_data in training_points:
model = ClassificationConvNet(ConvNeuralNet(), ClassificationOutputLayer()).to(device)
sampled_train_loader, sampled_val_loader = get_random_sample_train_val(train_dataset, val_dataset, batch_size, N_train_data)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)
# Update the train function call to get training costs
my_epoch, my_train_cost, my_val_cost, my_test_cost = train(
model,
sampled_train_loader,
sampled_val_loader,
test_loader_original,
cost_classification,
optimizer,
epochs_max_classification,
acc_flag_classification,
triplet_flag_classification,
task_name_classification,
N_train_data
)
my_epoch_Classification.append(my_epoch)
my_train_cost_Classification.append(my_train_cost)
my_val_cost_Classification.append(my_val_cost)
my_test_cost_Classification.append(my_test_cost)
# Compute predictions and confusion matrix for the validation set
all_preds = []
all_labels = []
model.eval()
with torch.no_grad():
for batch_idx, (X, y) in enumerate(sampled_val_loader):
X, y = X.to(device), y.to(device)
predictions = model(X)
_, predicted_classes = torch.max(predictions, 1)
all_preds.extend(predicted_classes.cpu().numpy())
all_labels.extend(y.cpu().numpy())
# Compute confusion matrix
conf_matrix = confusion_matrix(all_labels, all_preds)
conf_matrices.append((N_train_data, conf_matrix)) # Store the confusion matrix with the number of training points
# Compute predictions and confusion matrix for the validation set
all_preds = []
all_labels = []
model.eval()
with torch.no_grad():
for batch_idx, (X, y) in enumerate(sampled_val_loader):
X, y = X.to(device), y.to(device)
predictions = model(X)
_, predicted_classes = torch.max(predictions, 1)
all_preds.extend(predicted_classes.cpu().numpy())
all_labels.extend(y.cpu().numpy())
# Compute confusion matrix
conf_matrix = confusion_matrix(all_labels, all_preds)
conf_matrices.append((N_train_data, conf_matrix)) # Store the confusion matrix with the number of training points
Epoch: 1| Train cost: 2.30030| Train acc: 0.20000| Val cost: 2.30344| Val acc: 0.10000| Test cost: 2.30159| Test acc: 0.09972
Saving the model: models/ConvNet_classification_10_epoch_1.pth
Epoch: 2| Train cost: 2.29476| Train acc: 0.20000| Val cost: 2.30213| Val acc: 0.10000| Test cost: 2.30087| Test acc: 0.10171
Saving the model: models/ConvNet_classification_10_epoch_2.pth
Epoch: 3| Train cost: 2.28905| Train acc: 0.30000| Val cost: 2.30084| Val acc: 0.10000| Test cost: 2.30005| Test acc: 0.13256
Saving the model: models/ConvNet_classification_10_epoch_3.pth
Epoch: 4| Train cost: 2.28218| Train acc: 0.40000| Val cost: 2.29938| Val acc: 0.10000| Test cost: 2.29908| Test acc: 0.15545
Saving the model: models/ConvNet_classification_10_epoch_4.pth
Epoch: 5| Train cost: 2.27340| Train acc: 0.40000| Val cost: 2.29780| Val acc: 0.10000| Test cost: 2.29780| Test acc: 0.16939
Saving the model: models/ConvNet_classification_10_epoch_5.pth
Epoch: 6| Train cost: 2.26213| Train acc: 0.40000| Val cost: 2.29630| Val acc: 0.13333| Test cost: 2.29618| Test acc: 0.18312
Saving the model: models/ConvNet_classification_10_epoch_6.pth
Epoch: 7| Train cost: 2.24699| Train acc: 0.40000| Val cost: 2.29527| Val acc: 0.13333| Test cost: 2.29392| Test acc: 0.18710
Saving the model: models/ConvNet_classification_10_epoch_7.pth
Epoch: 8| Train cost: 2.22722| Train acc: 0.40000| Val cost: 2.29514| Val acc: 0.13333| Test cost: 2.29166| Test acc: 0.18869
Saving the model: models/ConvNet_classification_10_epoch_8.pth
Epoch: 9| Train cost: 2.20304| Train acc: 0.40000| Val cost: 2.29622| Val acc: 0.13333| Test cost: 2.28872| Test acc: 0.18969
Saving the model: models/ConvNet_classification_10_epoch_9.pth
Epoch: 10| Train cost: 2.17485| Train acc: 0.40000| Val cost: 2.29858| Val acc: 0.13333| Test cost: 2.28652| Test acc: 0.18830
Saving the model: models/ConvNet_classification_10_epoch_10.pth
Elapsed: 11.267536640167236
Epoch: 1| Train cost: 2.29918| Train acc: 0.23438| Val cost: 2.29809| Val acc: 0.16667| Test cost: 2.30008| Test acc: 0.09773
Saving the model: models/ConvNet_classification_100_epoch_1.pth
Epoch: 2| Train cost: 2.28924| Train acc: 0.16406| Val cost: 2.29134| Val acc: 0.16667| Test cost: 2.29702| Test acc: 0.09773
Saving the model: models/ConvNet_classification_100_epoch_2.pth
Epoch: 3| Train cost: 2.30070| Train acc: 0.10938| Val cost: 2.27972| Val acc: 0.16667| Test cost: 2.29231| Test acc: 0.09893
Saving the model: models/ConvNet_classification_100_epoch_3.pth
Epoch: 4| Train cost: 2.27172| Train acc: 0.16406| Val cost: 2.27588| Val acc: 0.16667| Test cost: 2.28427| Test acc: 0.09773
Saving the model: models/ConvNet_classification_100_epoch_4.pth
Epoch: 5| Train cost: 2.22435| Train acc: 0.21875| Val cost: 2.26439| Val acc: 0.16667| Test cost: 2.28069| Test acc: 0.09893
Saving the model: models/ConvNet_classification_100_epoch_5.pth
Epoch: 6| Train cost: 2.22952| Train acc: 0.16406| Val cost: 2.24435| Val acc: 0.16667| Test cost: 2.26329| Test acc: 0.10231
Saving the model: models/ConvNet_classification_100_epoch_6.pth
Epoch: 7| Train cost: 2.17872| Train acc: 0.27344| Val cost: 2.24259| Val acc: 0.20000| Test cost: 2.21076| Test acc: 0.27667
Saving the model: models/ConvNet_classification_100_epoch_7.pth
Epoch: 8| Train cost: 2.13272| Train acc: 0.32031| Val cost: 2.22052| Val acc: 0.20000| Test cost: 2.17802| Test acc: 0.28244
Saving the model: models/ConvNet_classification_100_epoch_8.pth
Epoch: 9| Train cost: 2.13415| Train acc: 0.33594| Val cost: 2.18109| Val acc: 0.23333| Test cost: 2.15290| Test acc: 0.28842
Saving the model: models/ConvNet_classification_100_epoch_9.pth
Epoch: 10| Train cost: 2.08263| Train acc: 0.37500| Val cost: 2.17162| Val acc: 0.36667| Test cost: 2.13271| Test acc: 0.37142
Saving the model: models/ConvNet_classification_100_epoch_10.pth
Elapsed: 11.347840309143066
Epoch: 1| Train cost: 2.22603| Train acc: 0.26465| Val cost: 2.02347| Val acc: 0.50521| Test cost: 2.02995| Test acc: 0.49542
Saving the model: models/ConvNet_classification_1000_epoch_1.pth
Epoch: 2| Train cost: 1.87207| Train acc: 0.61523| Val cost: 1.77983| Val acc: 0.69219| Test cost: 1.78431| Test acc: 0.68869
Saving the model: models/ConvNet_classification_1000_epoch_2.pth
Epoch: 3| Train cost: 1.70036| Train acc: 0.78027| Val cost: 1.69686| Val acc: 0.79271| Test cost: 1.70968| Test acc: 0.76154
Saving the model: models/ConvNet_classification_1000_epoch_3.pth
Epoch: 4| Train cost: 1.68390| Train acc: 0.78418| Val cost: 1.62508| Val acc: 0.86719| Test cost: 1.66928| Test acc: 0.80195
Saving the model: models/ConvNet_classification_1000_epoch_4.pth
Epoch: 5| Train cost: 1.64100| Train acc: 0.83008| Val cost: 1.67413| Val acc: 0.79271| Test cost: 1.67648| Test acc: 0.78861
Saving the model: models/ConvNet_classification_1000_epoch_5.pth
Epoch: 6| Train cost: 1.63098| Train acc: 0.83398| Val cost: 1.66576| Val acc: 0.80260| Test cost: 1.65673| Test acc: 0.81150
Saving the model: models/ConvNet_classification_1000_epoch_6.pth
Epoch: 7| Train cost: 1.61839| Train acc: 0.84961| Val cost: 1.65835| Val acc: 0.81615| Test cost: 1.63493| Test acc: 0.82902
Saving the model: models/ConvNet_classification_1000_epoch_7.pth
Epoch: 8| Train cost: 1.60526| Train acc: 0.85742| Val cost: 1.64911| Val acc: 0.81615| Test cost: 1.64544| Test acc: 0.82006
Saving the model: models/ConvNet_classification_1000_epoch_8.pth
Epoch: 9| Train cost: 1.61448| Train acc: 0.84766| Val cost: 1.61026| Val acc: 0.84948| Test cost: 1.62853| Test acc: 0.83599
Saving the model: models/ConvNet_classification_1000_epoch_9.pth
Epoch: 10| Train cost: 1.59131| Train acc: 0.87305| Val cost: 1.62935| Val acc: 0.84062| Test cost: 1.62815| Test acc: 0.83380
Saving the model: models/ConvNet_classification_1000_epoch_10.pth
Elapsed: 14.446405410766602
Epoch: 1| Train cost: 1.67816| Train acc: 0.80122| Val cost: 1.54842| Val acc: 0.91557| Test cost: 1.53607| Test acc: 0.93113
Saving the model: models/ConvNet_classification_10000_epoch_1.pth
Epoch: 2| Train cost: 1.52944| Train acc: 0.93510| Val cost: 1.52355| Val acc: 0.94161| Test cost: 1.51787| Test acc: 0.94566
Saving the model: models/ConvNet_classification_10000_epoch_2.pth
Epoch: 3| Train cost: 1.50815| Train acc: 0.95487| Val cost: 1.51061| Val acc: 0.94965| Test cost: 1.50064| Test acc: 0.96238
Saving the model: models/ConvNet_classification_10000_epoch_3.pth
Epoch: 4| Train cost: 1.49887| Train acc: 0.96366| Val cost: 1.50931| Val acc: 0.95446| Test cost: 1.50399| Test acc: 0.95900
Saving the model: models/ConvNet_classification_10000_epoch_4.pth
Epoch: 5| Train cost: 1.49510| Train acc: 0.96735| Val cost: 1.49687| Val acc: 0.96483| Test cost: 1.49927| Test acc: 0.96158
Saving the model: models/ConvNet_classification_10000_epoch_5.pth
Epoch: 6| Train cost: 1.48914| Train acc: 0.97304| Val cost: 1.48913| Val acc: 0.97286| Test cost: 1.49043| Test acc: 0.97193
Saving the model: models/ConvNet_classification_10000_epoch_6.pth
Epoch: 7| Train cost: 1.48572| Train acc: 0.97624| Val cost: 1.49966| Val acc: 0.96180| Test cost: 1.50696| Test acc: 0.95482
Saving the model: models/ConvNet_classification_10000_epoch_7.pth
Epoch: 8| Train cost: 1.48543| Train acc: 0.97624| Val cost: 1.49145| Val acc: 0.96875| Test cost: 1.48952| Test acc: 0.97154
Saving the model: models/ConvNet_classification_10000_epoch_8.pth
Epoch: 9| Train cost: 1.48626| Train acc: 0.97534| Val cost: 1.48897| Val acc: 0.97321| Test cost: 1.48998| Test acc: 0.97094
Saving the model: models/ConvNet_classification_10000_epoch_9.pth
Epoch: 10| Train cost: 1.47923| Train acc: 0.98263| Val cost: 1.49227| Val acc: 0.96875| Test cost: 1.48878| Test acc: 0.97253
Saving the model: models/ConvNet_classification_10000_epoch_10.pth
Elapsed: 45.01122760772705
Test performance#
The test performance of the model is evaluated by plotting the test cost across training epochs for different sample sizes.
# Create a single plot for all training costs with a logarithmic scale
with plt.xkcd():
plt.figure(figsize=(8, 6)) # Set the figure size
for i, n in enumerate(training_points):
epochs = my_epoch_Classification[i]
test_cost = my_test_cost_Classification[i]
plt.plot(epochs, test_cost, marker='o', linestyle='-', label=f'{n} training points')
plt.xlabel('Epochs')
plt.ylabel('Test cost (log scale)')
plt.title('Test cost over epochs for different training points (classification)')
plt.yscale('log')
plt.legend()
plt.grid(True)
plt.show()
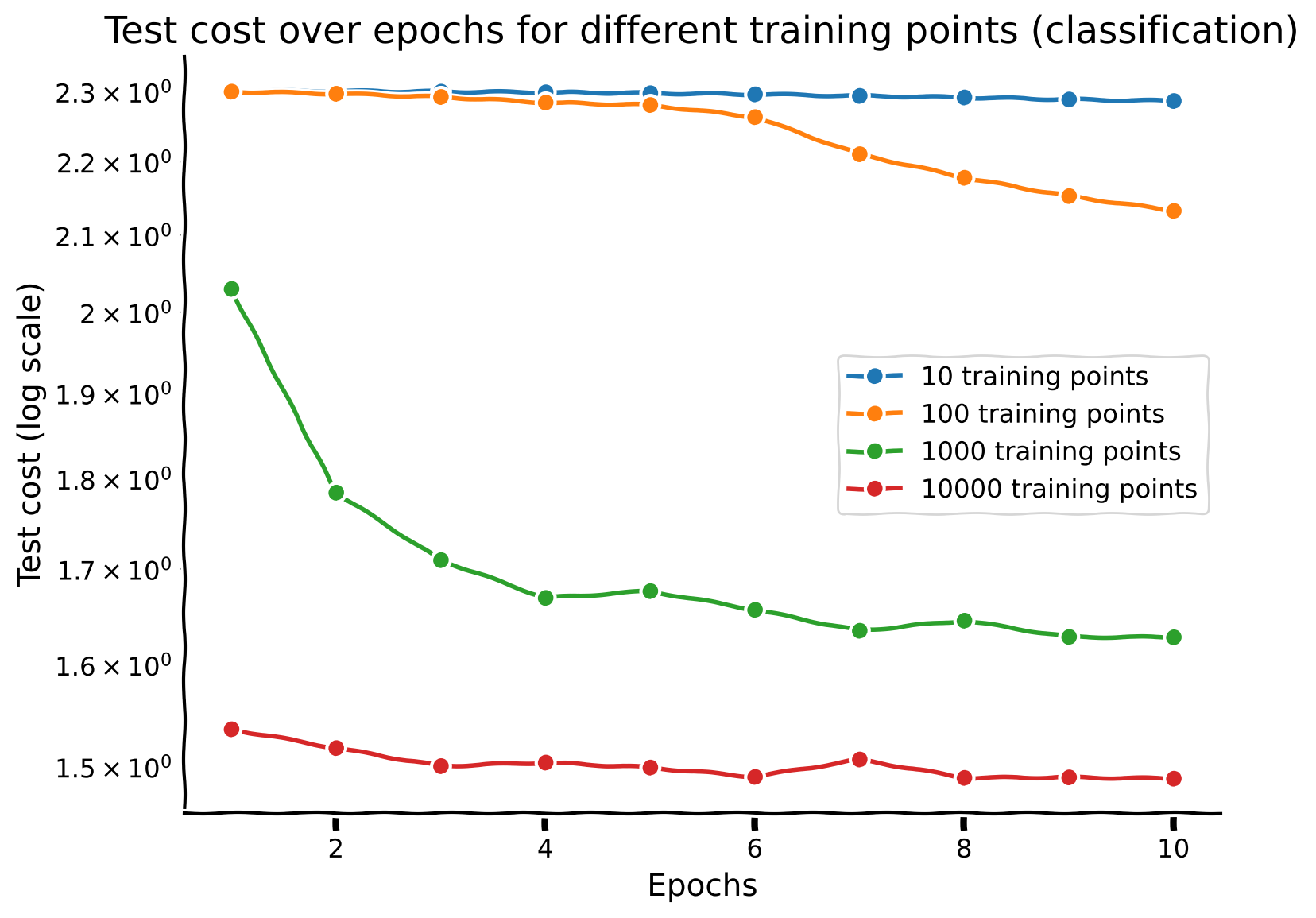
Discussion point 1#
Now that you have trained your network with different sample sizes, plot the performance on the test dataset for each network across epochs. How does sample size interact with number of training epochs?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Discussion_Point_1")
Section 1.2: Regression#
After examining the use of network architecture for digit classification, we now transition to a regression task using the same architecture. We are going to pick a very simple output task that is not directly related to the classification or the identification of the digits. In this task, given an image of a handwritten digit, our objective is to predict the number of pixels that are ‘ON’ (i.e., pixel values greater than 0.5). This can be achieved by the network performing operations similar to the simple addition of pixels (though it might still take time and data for the network to find this simple solution). Thus, we don’t expect that the network will learn rich representations that are useful for other tasks, such as classification.
Task objective#
This regression task, while relatively simple as it involves summing pixel values, serves to illustrate how well a Convolutional Neural Network (CNN) can adapt to learning a continuous output instead of discrete class labels.
Output layer#
The output layer for this regression task consists of a single node that predicts the number of ‘ON’ pixels in the image. This necessitates a different cost function compared to the classification task.
class RegressionOutputLayer(nn.Module):
def __init__(self):
super(RegressionOutputLayer, self).__init__()
self.fc = nn.Linear(LATENT_DIM, 1)
def forward(self, x):
x = self.fc(x)
return x
Here, RegressionOutputLayer outputs a single continuous value.
Code exercise 2: Cost function#
Here we implement the mean squared error (MSE) loss, which measures the average squared difference between the predicted and actual pixel values:
where:
\(N\) is the number of sample images
\(y_i\) is the true label for the \(i^{th}\) sample, the number of “ON” pixels
\(\mu_i = \text{CNN}(x_i)\) is the output of the model for the \(i^{th}\) sample image
############################################################
# Hint for criterion: The criterion used for regression tasks is designed
# to minimize the average squared difference between predicted and actual values.
# Hint for cost: To compute the cost, apply the criterion function to
# the predicted output and the actual target values, which will return the mean squared error loss.
raise NotImplementedError("Student exercise")
############################################################
def cost_regression(output, target):
criterion = ...
cost = ...
return cost
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Cost_Function_2")
This cost function computes the MSE loss between the predicted number of ‘ON’ pixels and the actual count of ‘ON’ pixels in the image, guiding the model to make accurate continuous predictions.
Training#
We train the network on varying dataset sizes (10, 100, 1000, 10000) to observe the impact of sample size on the model’s performance.
class RegressionConvNet(nn.Module):
def __init__(self, ConvNet, Output):
super(RegressionConvNet, self).__init__()
self.ConvNet = ConvNet
self.Output = Output
def forward(self, x):
conv_intermediate = self.ConvNet(x)
output = self.Output(conv_intermediate)
return output
The RegressionConvNet integrates the convolutional feature extraction network with the regression output layer.
Dataset preparation#
We adapt the MNIST dataset for the regression task by computing the number of ‘ON’ pixels for each image.
class RegressionMNIST(torch.utils.data.Dataset):
def __init__(self, mnist_dataset):
self.dataset = mnist_dataset.dataset
def __getitem__(self, index):
X, _ = self.dataset[index]
updated_label = torch.sum(X > 0.0).float() / X.shape[-1] ** 2 - 0.1307
return X, updated_label
def __len__(self):
return len(self.dataset)
This custom Dataset class transforms the images and computes the target values required for our regression task.
Model training and evaluation#
We initialize datasets and data loaders for the regression task, and define functions to evaluate models across different sample sizes.
set_seed(42)
training_points = np.array([10, 100, 1000, 10000])
task_name_regression = "regression"
acc_flag = False
triplet_flag = False
epochs_max_regression = 10
my_epoch_Regression = []
my_train_cost_Regression = []
my_val_cost_Regression = []
my_test_cost_Regression = []
train_dataset_regression = RegressionMNIST(train_dataset)
val_dataset_regression = RegressionMNIST(val_dataset)
test_dataset_original_regression = RegressionMNIST(test_dataset_original)
test_loader_original_regression = torch.utils.data.DataLoader(dataset = test_dataset_original_regression,
batch_size = batch_size,
shuffle = True)
for N_train_data in training_points:
model = RegressionConvNet(ConvNeuralNet(), RegressionOutputLayer()).to(device)
sampled_train_loader, sampled_val_loader = get_random_sample_train_val(train_dataset_regression, val_dataset_regression, batch_size, N_train_data)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)
my_epoch, my_train_cost, my_val_cost, my_test_cost = train(model, sampled_train_loader, sampled_val_loader, test_loader_original_regression, cost_regression, optimizer, epochs_max_regression, acc_flag, triplet_flag, task_name_regression, N_train_data)
my_epoch_Regression.append(my_epoch)
my_train_cost_Regression.append(my_train_cost) # Append the training costs
my_val_cost_Regression.append(my_val_cost) # Append the val costs
my_test_cost_Regression.append(my_test_cost) # Append the test costs
Epoch: 1| Train cost: 0.00267| Val cost: 0.02717| Test cost: 0.02624|
Saving the model: models/ConvNet_regression_10_epoch_1.pth
Epoch: 2| Train cost: 0.01898| Val cost: 0.00730| Test cost: 0.00691|
Saving the model: models/ConvNet_regression_10_epoch_2.pth
Epoch: 3| Train cost: 0.00361| Val cost: 0.00320| Test cost: 0.00301|
Saving the model: models/ConvNet_regression_10_epoch_3.pth
Epoch: 4| Train cost: 0.00313| Val cost: 0.00431| Test cost: 0.00419|
Saving the model: models/ConvNet_regression_10_epoch_4.pth
Epoch: 5| Train cost: 0.00580| Val cost: 0.00449| Test cost: 0.00437|
Saving the model: models/ConvNet_regression_10_epoch_5.pth
Epoch: 6| Train cost: 0.00594| Val cost: 0.00393| Test cost: 0.00380|
Saving the model: models/ConvNet_regression_10_epoch_6.pth
Epoch: 7| Train cost: 0.00483| Val cost: 0.00340| Test cost: 0.00324|
Saving the model: models/ConvNet_regression_10_epoch_7.pth
Epoch: 8| Train cost: 0.00368| Val cost: 0.00314| Test cost: 0.00295|
Saving the model: models/ConvNet_regression_10_epoch_8.pth
Epoch: 9| Train cost: 0.00282| Val cost: 0.00318| Test cost: 0.00295|
Saving the model: models/ConvNet_regression_10_epoch_9.pth
Epoch: 10| Train cost: 0.00229| Val cost: 0.00346| Test cost: 0.00318|
Saving the model: models/ConvNet_regression_10_epoch_10.pth
Elapsed: 25.75820279121399
Epoch: 1| Train cost: 0.00471| Val cost: 0.00265| Test cost: 0.00336|
Saving the model: models/ConvNet_regression_100_epoch_1.pth
Epoch: 2| Train cost: 0.00352| Val cost: 0.00230| Test cost: 0.00295|
Saving the model: models/ConvNet_regression_100_epoch_2.pth
Epoch: 3| Train cost: 0.00279| Val cost: 0.00258| Test cost: 0.00311|
Saving the model: models/ConvNet_regression_100_epoch_3.pth
Epoch: 4| Train cost: 0.00251| Val cost: 0.00248| Test cost: 0.00302|
Saving the model: models/ConvNet_regression_100_epoch_4.pth
Epoch: 5| Train cost: 0.00324| Val cost: 0.00231| Test cost: 0.00290|
Saving the model: models/ConvNet_regression_100_epoch_5.pth
Epoch: 6| Train cost: 0.00261| Val cost: 0.00227| Test cost: 0.00290|
Saving the model: models/ConvNet_regression_100_epoch_6.pth
Epoch: 7| Train cost: 0.00248| Val cost: 0.00228| Test cost: 0.00291|
Saving the model: models/ConvNet_regression_100_epoch_7.pth
Epoch: 8| Train cost: 0.00289| Val cost: 0.00228| Test cost: 0.00289|
Saving the model: models/ConvNet_regression_100_epoch_8.pth
Epoch: 9| Train cost: 0.00256| Val cost: 0.00230| Test cost: 0.00289|
Saving the model: models/ConvNet_regression_100_epoch_9.pth
Epoch: 10| Train cost: 0.00286| Val cost: 0.00235| Test cost: 0.00292|
Saving the model: models/ConvNet_regression_100_epoch_10.pth
Elapsed: 26.384212017059326
Epoch: 1| Train cost: 0.00513| Val cost: 0.00351| Test cost: 0.00298|
Saving the model: models/ConvNet_regression_1000_epoch_1.pth
Epoch: 2| Train cost: 0.00303| Val cost: 0.00361| Test cost: 0.00293|
Saving the model: models/ConvNet_regression_1000_epoch_2.pth
Epoch: 3| Train cost: 0.00303| Val cost: 0.00372| Test cost: 0.00308|
Saving the model: models/ConvNet_regression_1000_epoch_3.pth
Epoch: 4| Train cost: 0.00310| Val cost: 0.00321| Test cost: 0.00292|
Saving the model: models/ConvNet_regression_1000_epoch_4.pth
Epoch: 5| Train cost: 0.00306| Val cost: 0.00325| Test cost: 0.00294|
Saving the model: models/ConvNet_regression_1000_epoch_5.pth
Epoch: 6| Train cost: 0.00331| Val cost: 0.00386| Test cost: 0.00306|
Saving the model: models/ConvNet_regression_1000_epoch_6.pth
Epoch: 7| Train cost: 0.00305| Val cost: 0.00322| Test cost: 0.00290|
Saving the model: models/ConvNet_regression_1000_epoch_7.pth
Epoch: 8| Train cost: 0.00304| Val cost: 0.00315| Test cost: 0.00291|
Saving the model: models/ConvNet_regression_1000_epoch_8.pth
Epoch: 9| Train cost: 0.00305| Val cost: 0.00306| Test cost: 0.00293|
Saving the model: models/ConvNet_regression_1000_epoch_9.pth
Epoch: 10| Train cost: 0.00295| Val cost: 0.00342| Test cost: 0.00293|
Saving the model: models/ConvNet_regression_1000_epoch_10.pth
Elapsed: 29.754976272583008
Epoch: 1| Train cost: 0.00293| Val cost: 0.00310| Test cost: 0.00293|
Saving the model: models/ConvNet_regression_10000_epoch_1.pth
Epoch: 2| Train cost: 0.00290| Val cost: 0.00307| Test cost: 0.00291|
Saving the model: models/ConvNet_regression_10000_epoch_2.pth
Epoch: 3| Train cost: 0.00290| Val cost: 0.00306| Test cost: 0.00289|
Saving the model: models/ConvNet_regression_10000_epoch_3.pth
Epoch: 4| Train cost: 0.00289| Val cost: 0.00306| Test cost: 0.00288|
Saving the model: models/ConvNet_regression_10000_epoch_4.pth
Epoch: 5| Train cost: 0.00289| Val cost: 0.00307| Test cost: 0.00289|
Saving the model: models/ConvNet_regression_10000_epoch_5.pth
Epoch: 6| Train cost: 0.00288| Val cost: 0.00305| Test cost: 0.00288|
Saving the model: models/ConvNet_regression_10000_epoch_6.pth
Epoch: 7| Train cost: 0.00289| Val cost: 0.00307| Test cost: 0.00289|
Saving the model: models/ConvNet_regression_10000_epoch_7.pth
Epoch: 8| Train cost: 0.00289| Val cost: 0.00309| Test cost: 0.00290|
Saving the model: models/ConvNet_regression_10000_epoch_8.pth
Epoch: 9| Train cost: 0.00289| Val cost: 0.00307| Test cost: 0.00289|
Saving the model: models/ConvNet_regression_10000_epoch_9.pth
Epoch: 10| Train cost: 0.00288| Val cost: 0.00307| Test cost: 0.00289|
Saving the model: models/ConvNet_regression_10000_epoch_10.pth
Elapsed: 64.51416850090027
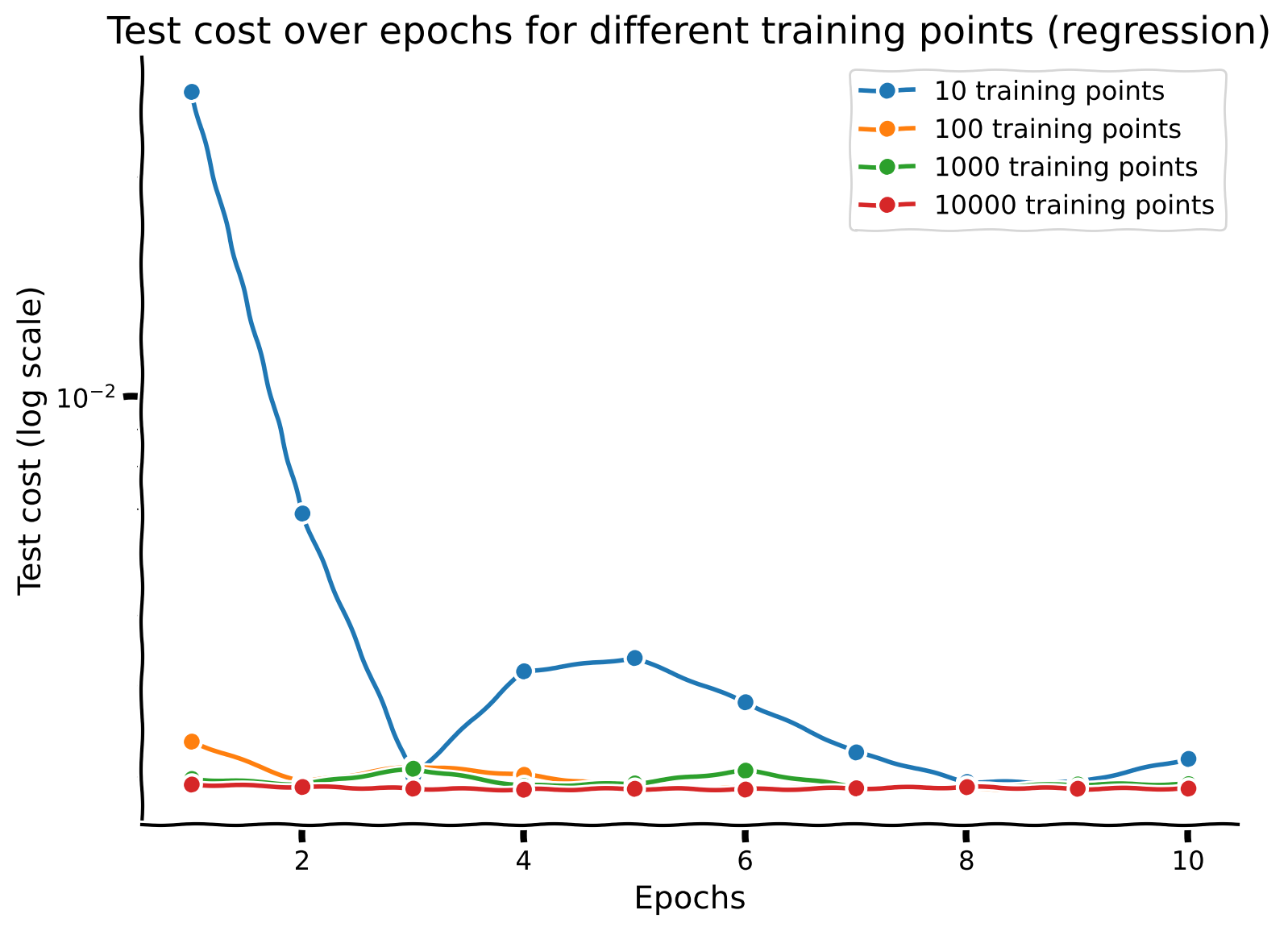
Discussion point 2#
Now that you have trained your network with different sample sizes, plot the test performance for each network across epochs. How does sample size interact with the number of training epochs?
# Create a single plot for all test costs with a logarithmic scale
with plt.xkcd():
plt.figure(figsize=(8, 6)) #Set the figure size
for i, n in enumerate(training_points):
epochs = my_epoch_Regression[i]
test_cost = my_test_cost_Regression[i]
plt.plot(epochs, test_cost, marker='o', linestyle='-', label=f'{n} training points')
plt.xlabel('Epochs')
plt.ylabel('Test cost (log scale)')
plt.title('Test cost over epochs for different training points (regression)')
plt.yscale('log')
plt.legend()
plt.grid(True)
plt.show()
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Discussion_Point_2")
Section 1.3: Auto-encoder#
Now, we extend our network architecture to an unsupervised learning task. Specifically, we aim to develop an autoencoder capable of compressing an image of a handwritten digit into a lower-dimensional representation of size \(M\) and then reconstructing the original image with minimal error.
Autoencoder architecture#
An autoencoder consists of three main components: an encoder, a bottleneck layer, and a decoder. The encoder compresses the input into a smaller representation, the bottleneck layer holds this compressed representation, and the decoder reconstructs the original image from this representation.
class Autoencoder(nn.Module):
def __init__(self, encoder, bottleneck, decoder):
super(Autoencoder, self).__init__()
self.encoder = encoder
self.bottleneck = bottleneck
self.decoder = decoder
def forward(self, x):
encoded = self.encoder(x)
bottlenecked = self.bottleneck(encoded)
decoded = self.decoder(bottlenecked)
return decoded
In our architecture:
The encoder will be a CNN
The bottleneck layer will be a fully connected layer of size \(M\).
The decoder layer will be a deconvolutional neural network, which does the operations of a CNN in reverse: it goes from a dense representation to a low-resolution image, and then upsamples that image in subsequent layers.
Code exercise 3: Cost Function#
We’ll use Mean Squared Error (MSE) loss for the autoencoder. This loss function measures the average squared difference between the original and reconstructed images, guiding the network to minimize the reconstruction error.
############################################################
# Hint for output_flat: To flatten the output tensor for comparison, reshape it to
# have a size of (batch_size, -1) where batch_size is the number of samples.
# Hint for target_flat: Similarly, flatten the target tensor to match the shape
# of the flattened output tensor, ensuring it has a size of (batch_size, -1).
raise NotImplementedError("Student exercise")
############################################################
def cost_autoencoder(output, target):
criterion = nn.MSELoss()
output_flat = ...
target_flat = ...
cost = criterion(output_flat, target_flat)
return cost
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Cost_Function_3")
Dataset#
This custom Dataset class prepares the MNIST images for the autoencoder task, applying necessary transformations and using the images themselves as targets for reconstruction.
class AutoencoderMNIST(torch.utils.data.Dataset):
def __init__(self, mnist_dataset):
self.dataset = mnist_dataset
def __getitem__(self, index):
X, y = self.dataset[index]
return X, X
def __len__(self):
return len(self.dataset)
Model training and evaluation#
We train separate autoencoder networks on different dataset sizes (10, 100, 1000, 10000) to analyze how the amount of data influences the model’s performance. The training continues until the validation performance ceases to improve, and test performance is recorded at each epoch.
Note: we also plot here some of the original validation images and how well they were reconstructed by each network after 10 iterations.
set_seed(42)
# Define constants for autoencoder task
training_points = np.array([10, 100, 1000, 10000])
task_name_autoencoder = "autoencoder"
# Size of the bottleneck. We'll keep this consistent across experiments.
M = 16
acc_flag_autoencoder = False
triplet_flag_autoencoder = False
epochs_max_autoencoder = 10
train_dataset_autoencoder = AutoencoderMNIST(train_dataset)
val_dataset_autoencoder = AutoencoderMNIST(val_dataset)
test_dataset_original_autoencoder = AutoencoderMNIST(test_dataset_original)
test_loader_original_autoencoder = torch.utils.data.DataLoader(
dataset=test_dataset_original_autoencoder,
batch_size=batch_size,
shuffle=True
)
my_epoch_Autoencoder = []
my_train_cost_Autoencoder = []
my_val_cost_Autoencoder = []
my_test_cost_Autoencoder = []
reconstructions = []
for N_train_data in training_points:
model = Autoencoder(ConvNeuralNet(), BottleneckLayer(M), ConvNeuralNetDecoder(M)).to(device)
sampled_train_loader, sampled_val_loader = get_random_sample_train_val(
train_dataset_autoencoder,
val_dataset_autoencoder,
batch_size,
N_train_data
)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)
my_epoch, my_train_cost, my_val_cost, my_test_cost = train(
model,
sampled_train_loader,
sampled_val_loader,
test_loader_original_autoencoder,
cost_autoencoder,
optimizer,
epochs_max_autoencoder,
acc_flag_autoencoder,
triplet_flag_autoencoder,
task_name_autoencoder,
N_train_data
)
my_epoch_Autoencoder.append(my_epoch)
my_train_cost_Autoencoder.append(my_train_cost)
my_val_cost_Autoencoder.append(my_val_cost)
my_test_cost_Autoencoder.append(my_test_cost)
original_images = []
reconstructed_images = []
model.eval()
with torch.no_grad():
for batch_idx, (X, _) in enumerate(sampled_val_loader):
if batch_idx == 0:
X = X.to(device)
outputs = model(X)
orig = X.cpu().numpy()
original_images.extend(orig)
recon = outputs.cpu().numpy()
reconstructed_images.extend(recon)
plot_reconstructions(original_images, reconstructed_images, N_train_data, epochs_max_autoencoder)
break
reconstructions.append((N_train_data, original_images, reconstructed_images))
Epoch: 1| Train cost: 0.82655| Val cost: 0.93275| Test cost: 0.91777|
Saving the model: models/ConvNet_autoencoder_10_epoch_1.pth
Epoch: 2| Train cost: 0.82601| Val cost: 0.93241| Test cost: 0.91647|
Saving the model: models/ConvNet_autoencoder_10_epoch_2.pth
Epoch: 3| Train cost: 0.82552| Val cost: 0.93208| Test cost: 0.91641|
Saving the model: models/ConvNet_autoencoder_10_epoch_3.pth
Epoch: 4| Train cost: 0.82504| Val cost: 0.93175| Test cost: 0.91530|
Saving the model: models/ConvNet_autoencoder_10_epoch_4.pth
Epoch: 5| Train cost: 0.82457| Val cost: 0.93140| Test cost: 0.91583|
Saving the model: models/ConvNet_autoencoder_10_epoch_5.pth
Epoch: 6| Train cost: 0.82409| Val cost: 0.93102| Test cost: 0.91561|
Saving the model: models/ConvNet_autoencoder_10_epoch_6.pth
Epoch: 7| Train cost: 0.82359| Val cost: 0.93060| Test cost: 0.91493|
Saving the model: models/ConvNet_autoencoder_10_epoch_7.pth
Epoch: 8| Train cost: 0.82304| Val cost: 0.93011| Test cost: 0.91440|
Saving the model: models/ConvNet_autoencoder_10_epoch_8.pth
Epoch: 9| Train cost: 0.82244| Val cost: 0.92949| Test cost: 0.91384|
Saving the model: models/ConvNet_autoencoder_10_epoch_9.pth
Epoch: 10| Train cost: 0.82173| Val cost: 0.92875| Test cost: 0.91289|
Saving the model: models/ConvNet_autoencoder_10_epoch_10.pth
Elapsed: 12.266870021820068

Epoch: 1| Train cost: 0.94496| Val cost: 1.09508| Test cost: 0.92759|
Saving the model: models/ConvNet_autoencoder_100_epoch_1.pth
Epoch: 2| Train cost: 0.84873| Val cost: 1.08896| Test cost: 0.92309|
Saving the model: models/ConvNet_autoencoder_100_epoch_2.pth
Epoch: 3| Train cost: 0.89585| Val cost: 1.08088| Test cost: 0.91713|
Saving the model: models/ConvNet_autoencoder_100_epoch_3.pth
Epoch: 4| Train cost: 0.89527| Val cost: 1.06307| Test cost: 0.90104|
Saving the model: models/ConvNet_autoencoder_100_epoch_4.pth
Epoch: 5| Train cost: 0.90988| Val cost: 0.99760| Test cost: 0.84872|
Saving the model: models/ConvNet_autoencoder_100_epoch_5.pth
Epoch: 6| Train cost: 0.80133| Val cost: 0.85810| Test cost: 0.75280|
Saving the model: models/ConvNet_autoencoder_100_epoch_6.pth
Epoch: 7| Train cost: 0.73808| Val cost: 0.82491| Test cost: 0.72001|
Saving the model: models/ConvNet_autoencoder_100_epoch_7.pth
Epoch: 8| Train cost: 0.67040| Val cost: 0.83882| Test cost: 0.72085|
Saving the model: models/ConvNet_autoencoder_100_epoch_8.pth
Epoch: 9| Train cost: 0.68790| Val cost: 0.80060| Test cost: 0.69180|
Saving the model: models/ConvNet_autoencoder_100_epoch_9.pth
Epoch: 10| Train cost: 0.67945| Val cost: 0.77658| Test cost: 0.67812|
Saving the model: models/ConvNet_autoencoder_100_epoch_10.pth
Elapsed: 12.731178283691406

Epoch: 1| Train cost: 0.79917| Val cost: 0.67037| Test cost: 0.67448|
Saving the model: models/ConvNet_autoencoder_1000_epoch_1.pth
Epoch: 2| Train cost: 0.62655| Val cost: 0.61430| Test cost: 0.61075|
Saving the model: models/ConvNet_autoencoder_1000_epoch_2.pth
Epoch: 3| Train cost: 0.59072| Val cost: 0.59552| Test cost: 0.58794|
Saving the model: models/ConvNet_autoencoder_1000_epoch_3.pth
Epoch: 4| Train cost: 0.57191| Val cost: 0.58535| Test cost: 0.57859|
Saving the model: models/ConvNet_autoencoder_1000_epoch_4.pth
Epoch: 5| Train cost: 0.56554| Val cost: 0.56753| Test cost: 0.56739|
Saving the model: models/ConvNet_autoencoder_1000_epoch_5.pth
Epoch: 6| Train cost: 0.53882| Val cost: 0.54184| Test cost: 0.52921|
Saving the model: models/ConvNet_autoencoder_1000_epoch_6.pth
Epoch: 7| Train cost: 0.50869| Val cost: 0.52191| Test cost: 0.51086|
Saving the model: models/ConvNet_autoencoder_1000_epoch_7.pth
Epoch: 8| Train cost: 0.48314| Val cost: 0.47686| Test cost: 0.47093|
Saving the model: models/ConvNet_autoencoder_1000_epoch_8.pth
Epoch: 9| Train cost: 0.44747| Val cost: 0.44217| Test cost: 0.43576|
Saving the model: models/ConvNet_autoencoder_1000_epoch_9.pth
Epoch: 10| Train cost: 0.41884| Val cost: 0.43198| Test cost: 0.42414|
Saving the model: models/ConvNet_autoencoder_1000_epoch_10.pth
Elapsed: 16.397107124328613

Epoch: 1| Train cost: 0.56517| Val cost: 0.41709| Test cost: 0.42086|
Saving the model: models/ConvNet_autoencoder_10000_epoch_1.pth
Epoch: 2| Train cost: 0.35980| Val cost: 0.30554| Test cost: 0.30210|
Saving the model: models/ConvNet_autoencoder_10000_epoch_2.pth
Epoch: 3| Train cost: 0.27801| Val cost: 0.26395| Test cost: 0.25817|
Saving the model: models/ConvNet_autoencoder_10000_epoch_3.pth
Epoch: 4| Train cost: 0.24818| Val cost: 0.24584| Test cost: 0.24140|
Saving the model: models/ConvNet_autoencoder_10000_epoch_4.pth
Epoch: 5| Train cost: 0.23459| Val cost: 0.23393| Test cost: 0.23006|
Saving the model: models/ConvNet_autoencoder_10000_epoch_5.pth
Epoch: 6| Train cost: 0.22556| Val cost: 0.22720| Test cost: 0.22361|
Saving the model: models/ConvNet_autoencoder_10000_epoch_6.pth
Epoch: 7| Train cost: 0.21961| Val cost: 0.22285| Test cost: 0.21948|
Saving the model: models/ConvNet_autoencoder_10000_epoch_7.pth
Epoch: 8| Train cost: 0.21452| Val cost: 0.21692| Test cost: 0.21400|
Saving the model: models/ConvNet_autoencoder_10000_epoch_8.pth
Epoch: 9| Train cost: 0.20975| Val cost: 0.21320| Test cost: 0.21058|
Saving the model: models/ConvNet_autoencoder_10000_epoch_9.pth
Epoch: 10| Train cost: 0.20529| Val cost: 0.21036| Test cost: 0.20666|
Saving the model: models/ConvNet_autoencoder_10000_epoch_10.pth
Elapsed: 54.1287043094635

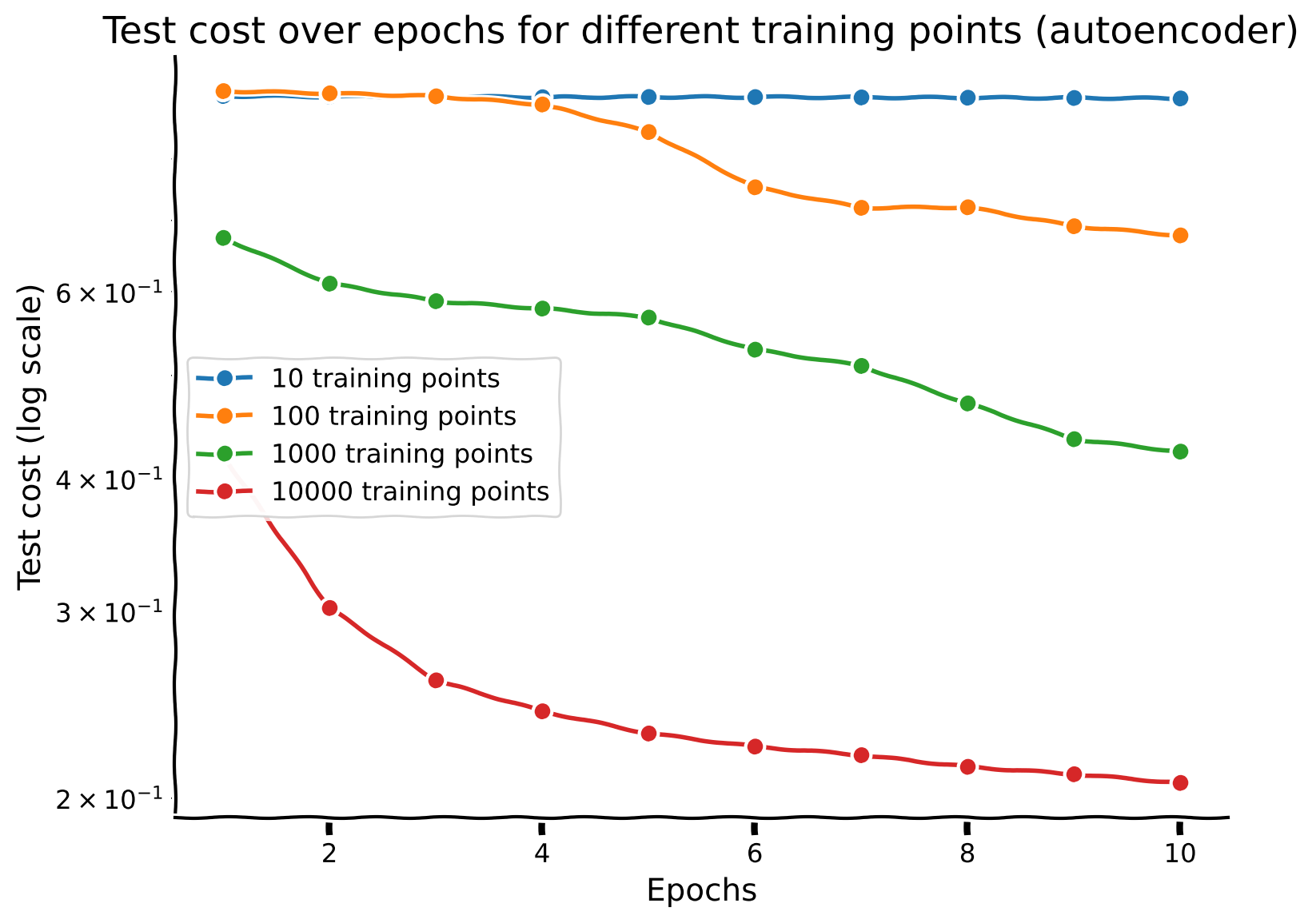
Discussion point 3#
Plot the performance of the network across epochs. What’s the relationship between sample size and iteration complexity?
What do you think of the images plotted above? Does the autoencoding task require more or less data than the two previous tasks (classification of digit and regression of number of ON pixels)?
# Create a single plot for all test costs with a logarithmic scale
with plt.xkcd():
plt.figure(figsize=(8, 6)) # Set the figure size
for i, n in enumerate(training_points):
epochs = my_epoch_Autoencoder[i]
test_cost = my_test_cost_Autoencoder[i]
plt.plot(epochs, test_cost, marker='o', linestyle='-', label=f'{n} training points')
plt.xlabel('Epochs')
plt.ylabel('Test cost (log scale)')
plt.title('Test cost over epochs for different training points (autoencoder)')
plt.yscale('log')
plt.legend()
plt.grid(True)
plt.show()
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Discussion_Point_3")
Section 1.4: Self-supervised - Inpainting#
In this section, we implement a self-supervised task using the same architecture. We define a patch of an image to be a small portion of the main image, of a specific patch window size. Given an full image of a handwritten digit with a patch of size \(N×N\) masked out, the objective is to reconstruct the image by accurately predicting the pixel values in the masked region. Thus, the network must use the surrounding context to effectively “inpaint” the missing portion.
Task objective#
The task is to build an autoencoder that can fill in missing parts of an image, a process known as inpainting. This involves training the model to reconstruct the entire image. Implicitly, the model will predict and reconstruct the masked regions of the image using the contextual information from the non-masked parts.
Important note: this is a simplified inpainting task and not how inpainting is usually defined. Usually, the region to be inpainted is provided as part of the input.
Random masking#
First, we implement a function to randomly mask a part of the image. This function will be used to generate the training data for our inpainting task.
def random_mask(images, mask_size=8):
"""
Randomly mask an N x N patch in a batch of images.
Parameters:
- images: A batch of images as a PyTorch tensor, shape (batch_size, channels, height, width)
- mask_size: Size of the square mask (N)
Returns:
- A new batch of images with the masked portions zeroed out.
"""
# Clone the images to avoid modifying the original data
obstructed_images = images.clone()
batch_size, height, width = images.size()
for i in range(batch_size):
# Choose a random location for the mask
y = np.random.randint(0, height - mask_size)
x = np.random.randint(0, width - mask_size)
# Apply the mask by setting the pixel values to 0 (or another value)
obstructed_images[i, y:y + mask_size, x:x + mask_size] = 0
return obstructed_images
Here’s one example of a masked image.
plt.figure(figsize=(4, 2))
ind = 12
img, label = train_dataset[ind]
plt.subplot(121)
plt.imshow(img.numpy().squeeze(), cmap='gray')
plt.title(f"Original")
plt.axis(False)
plt.tight_layout()
plt.subplot(122)
img_masked = random_mask(img, mask_size=12)
plt.imshow(img_masked.numpy().squeeze(), cmap='gray')
plt.title(f"Masked")
plt.axis(False)
plt.tight_layout()
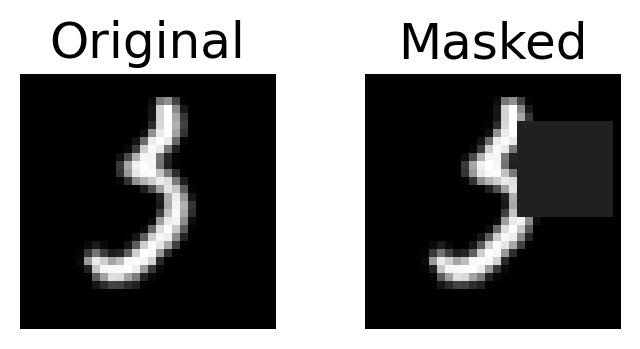
This function randomly places a N×N mask in each image by setting the pixel values within this region to zero (black).
Autoencoder Cost Function#
We re-use the same autoencoder architecture as in the previous sections, with an encoder, bottleneck layer, and decoder. We also use the Mean Squared Error (MSE) loss, as it measures the reconstruction error between the predicted and actual pixel values.
Dataset#
This custom Dataset class prepares the MNIST images for the inpainting task, applying necessary transformations and adding random masking to create the training data. We specify mask_size to be 8 in the __getitem__ function. This could be specified in the Dataset initializer (__init__) if we wanted to change it. For now, we will keep it to be 8.
class InpaintingMNIST(torch.utils.data.Dataset):
def __init__(self, mnist_dataset):
self.dataset = mnist_dataset
def __getitem__(self, index):
X, y = self.dataset[index]
obstructed = random_mask(X, mask_size=8)
return obstructed, X
def __len__(self):
return len(self.dataset)
Model training and evaluation#
We train the autoencoder on different dataset sizes (10, 100, 1000, 10000) to evaluate how the sample size affects the model’s performance. Training continues until validation performance stops improving, and test performance is recorded at each epoch.
# Define constants
set_seed(42)
training_points = np.array([10, 100, 1000, 10000])
task_name_inpainting = "inpainting"
acc_flag_inpainting = False
triplet_flag_inpainting = False
epochs_max_inpainting = 10
my_epoch_Inpainting = []
my_train_cost_Inpainting = []
my_val_cost_Inpainting = []
my_test_cost_Inpainting = []
reconstructions_inpainting = []
# Create inpainting versions of the training, validation, and test datasets
train_dataset_inpainting = InpaintingMNIST(train_dataset)
val_dataset_inpainting = InpaintingMNIST(val_dataset)
test_dataset_original_inpainting = InpaintingMNIST(test_dataset_original)
# Create a data loader for the inpainting test dataset
test_loader_original_inpainting = torch.utils.data.DataLoader(
dataset=test_dataset_original_inpainting,
batch_size=batch_size,
shuffle=True
)
for N_train_data in training_points:
model = Autoencoder(ConvNeuralNet(), BottleneckLayer(M), ConvNeuralNetDecoder(M)).to(device)
sampled_train_loader, sampled_val_loader = get_random_sample_train_val(
train_dataset_inpainting,
val_dataset_inpainting,
batch_size,
N_train_data
)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)
# Update the train function call to get training costs
my_epoch, my_train_cost, my_val_cost, my_test_cost = train(
model,
sampled_train_loader,
sampled_val_loader,
test_loader_original_inpainting,
cost_autoencoder,
optimizer,
epochs_max_inpainting,
acc_flag_inpainting,
triplet_flag_inpainting,
task_name_inpainting,
N_train_data
)
my_epoch_Inpainting.append(my_epoch)
my_train_cost_Inpainting.append(my_train_cost)
my_val_cost_Inpainting.append(my_val_cost)
my_test_cost_Inpainting.append(my_test_cost)
original_images = []
reconstructed_images = []
model.eval()
with torch.no_grad():
for batch_idx, (X, _) in enumerate(sampled_val_loader):
if batch_idx == 0: # Only visualize the first batch for simplicity
X = X.to(device)
outputs = model(X)
orig = X.cpu().numpy()
original_images.extend(orig)
recon = outputs.cpu().numpy()
reconstructed_images.extend(recon)
fig = plt.figure(figsize=(8, 4))
rows, cols = 2, 6
image_count = 1
for i in range(1,(rows*cols),2 ):
fig.add_subplot(rows, cols, i)
plt.imshow(np.squeeze(orig[image_count]), cmap='gray')
fig.add_subplot(rows, cols, i+1)
plt.imshow(np.squeeze(recon[image_count]), cmap='gray')
image_count+=1
break
plt.suptitle("Training for 10 epochs with {} points".format(N_train_data))
reconstructions_inpainting.append((N_train_data, original_images, reconstructed_images))
Epoch: 1| Train cost: 0.82655| Val cost: 0.93275| Test cost: 0.91777|
Saving the model: models/ConvNet_inpainting_10_epoch_1.pth
Epoch: 2| Train cost: 0.82601| Val cost: 0.93241| Test cost: 0.91647|
Saving the model: models/ConvNet_inpainting_10_epoch_2.pth
Epoch: 3| Train cost: 0.82552| Val cost: 0.93208| Test cost: 0.91641|
Saving the model: models/ConvNet_inpainting_10_epoch_3.pth
Epoch: 4| Train cost: 0.82504| Val cost: 0.93175| Test cost: 0.91530|
Saving the model: models/ConvNet_inpainting_10_epoch_4.pth
Epoch: 5| Train cost: 0.82457| Val cost: 0.93140| Test cost: 0.91583|
Saving the model: models/ConvNet_inpainting_10_epoch_5.pth
Epoch: 6| Train cost: 0.82409| Val cost: 0.93103| Test cost: 0.91561|
Saving the model: models/ConvNet_inpainting_10_epoch_6.pth
Epoch: 7| Train cost: 0.82359| Val cost: 0.93061| Test cost: 0.91493|
Saving the model: models/ConvNet_inpainting_10_epoch_7.pth
Epoch: 8| Train cost: 0.82305| Val cost: 0.93013| Test cost: 0.91441|
Saving the model: models/ConvNet_inpainting_10_epoch_8.pth
Epoch: 9| Train cost: 0.82245| Val cost: 0.92950| Test cost: 0.91386|
Saving the model: models/ConvNet_inpainting_10_epoch_9.pth
Epoch: 10| Train cost: 0.82175| Val cost: 0.92875| Test cost: 0.91291|
Saving the model: models/ConvNet_inpainting_10_epoch_10.pth
Elapsed: 14.715582847595215
Epoch: 1| Train cost: 0.94496| Val cost: 1.09508| Test cost: 0.92759|
Saving the model: models/ConvNet_inpainting_100_epoch_1.pth
Epoch: 2| Train cost: 0.84873| Val cost: 1.08895| Test cost: 0.92308|
Saving the model: models/ConvNet_inpainting_100_epoch_2.pth
Epoch: 3| Train cost: 0.89581| Val cost: 1.08073| Test cost: 0.91698|
Saving the model: models/ConvNet_inpainting_100_epoch_3.pth
Epoch: 4| Train cost: 0.89478| Val cost: 1.06119| Test cost: 0.89939|
Saving the model: models/ConvNet_inpainting_100_epoch_4.pth
Epoch: 5| Train cost: 0.90555| Val cost: 0.98824| Test cost: 0.84085|
Saving the model: models/ConvNet_inpainting_100_epoch_5.pth
Epoch: 6| Train cost: 0.79199| Val cost: 0.86862| Test cost: 0.76460|
Saving the model: models/ConvNet_inpainting_100_epoch_6.pth
Epoch: 7| Train cost: 0.73877| Val cost: 0.82494| Test cost: 0.71873|
Saving the model: models/ConvNet_inpainting_100_epoch_7.pth
Epoch: 8| Train cost: 0.67005| Val cost: 0.83807| Test cost: 0.71954|
Saving the model: models/ConvNet_inpainting_100_epoch_8.pth
Epoch: 9| Train cost: 0.68633| Val cost: 0.79788| Test cost: 0.69004|
Saving the model: models/ConvNet_inpainting_100_epoch_9.pth
Epoch: 10| Train cost: 0.67919| Val cost: 0.77445| Test cost: 0.67776|
Saving the model: models/ConvNet_inpainting_100_epoch_10.pth
Elapsed: 15.069083452224731
Epoch: 1| Train cost: 0.79506| Val cost: 0.67492| Test cost: 0.67748|
Saving the model: models/ConvNet_inpainting_1000_epoch_1.pth
Epoch: 2| Train cost: 0.62760| Val cost: 0.61575| Test cost: 0.61304|
Saving the model: models/ConvNet_inpainting_1000_epoch_2.pth
Epoch: 3| Train cost: 0.59319| Val cost: 0.59748| Test cost: 0.59038|
Saving the model: models/ConvNet_inpainting_1000_epoch_3.pth
Epoch: 4| Train cost: 0.57480| Val cost: 0.58742| Test cost: 0.58225|
Saving the model: models/ConvNet_inpainting_1000_epoch_4.pth
Epoch: 5| Train cost: 0.57000| Val cost: 0.57417| Test cost: 0.57503|
Saving the model: models/ConvNet_inpainting_1000_epoch_5.pth
Epoch: 6| Train cost: 0.56177| Val cost: 0.56145| Test cost: 0.55548|
Saving the model: models/ConvNet_inpainting_1000_epoch_6.pth
Epoch: 7| Train cost: 0.53659| Val cost: 0.54408| Test cost: 0.53667|
Saving the model: models/ConvNet_inpainting_1000_epoch_7.pth
Epoch: 8| Train cost: 0.52694| Val cost: 0.53012| Test cost: 0.52454|
Saving the model: models/ConvNet_inpainting_1000_epoch_8.pth
Epoch: 9| Train cost: 0.50664| Val cost: 0.50016| Test cost: 0.49167|
Saving the model: models/ConvNet_inpainting_1000_epoch_9.pth
Epoch: 10| Train cost: 0.47016| Val cost: 0.48963| Test cost: 0.47331|
Saving the model: models/ConvNet_inpainting_1000_epoch_10.pth
Elapsed: 19.548003911972046
Epoch: 1| Train cost: 0.58190| Val cost: 0.47491| Test cost: 0.48022|
Saving the model: models/ConvNet_inpainting_10000_epoch_1.pth
Epoch: 2| Train cost: 0.42642| Val cost: 0.37903| Test cost: 0.37737|
Saving the model: models/ConvNet_inpainting_10000_epoch_2.pth
Epoch: 3| Train cost: 0.32236| Val cost: 0.28765| Test cost: 0.28499|
Saving the model: models/ConvNet_inpainting_10000_epoch_3.pth
Epoch: 4| Train cost: 0.27336| Val cost: 0.26973| Test cost: 0.26776|
Saving the model: models/ConvNet_inpainting_10000_epoch_4.pth
Epoch: 5| Train cost: 0.25403| Val cost: 0.25183| Test cost: 0.24719|
Saving the model: models/ConvNet_inpainting_10000_epoch_5.pth
Epoch: 6| Train cost: 0.23719| Val cost: 0.23522| Test cost: 0.23156|
Saving the model: models/ConvNet_inpainting_10000_epoch_6.pth
Epoch: 7| Train cost: 0.22873| Val cost: 0.22697| Test cost: 0.22421|
Saving the model: models/ConvNet_inpainting_10000_epoch_7.pth
Epoch: 8| Train cost: 0.22193| Val cost: 0.23003| Test cost: 0.22663|
Saving the model: models/ConvNet_inpainting_10000_epoch_8.pth
Epoch: 9| Train cost: 0.21578| Val cost: 0.21727| Test cost: 0.21399|
Saving the model: models/ConvNet_inpainting_10000_epoch_9.pth
Epoch: 10| Train cost: 0.21112| Val cost: 0.21485| Test cost: 0.21163|
Saving the model: models/ConvNet_inpainting_10000_epoch_10.pth
Elapsed: 61.461453914642334
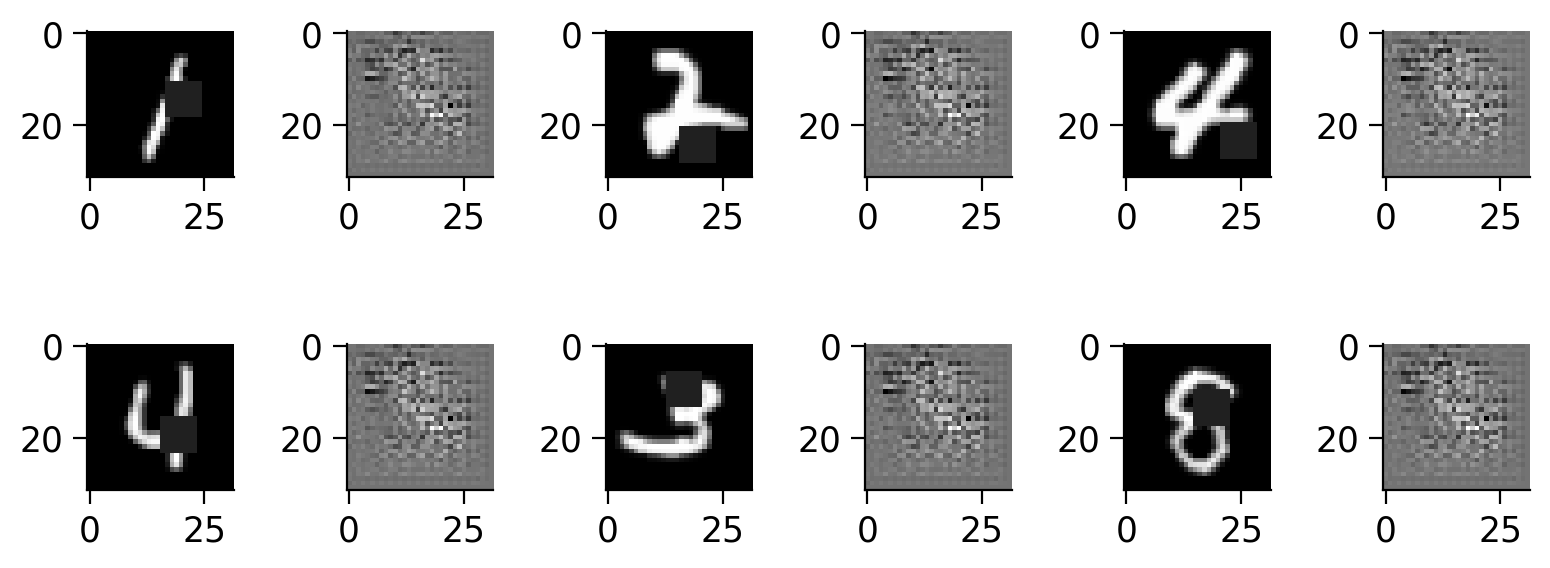
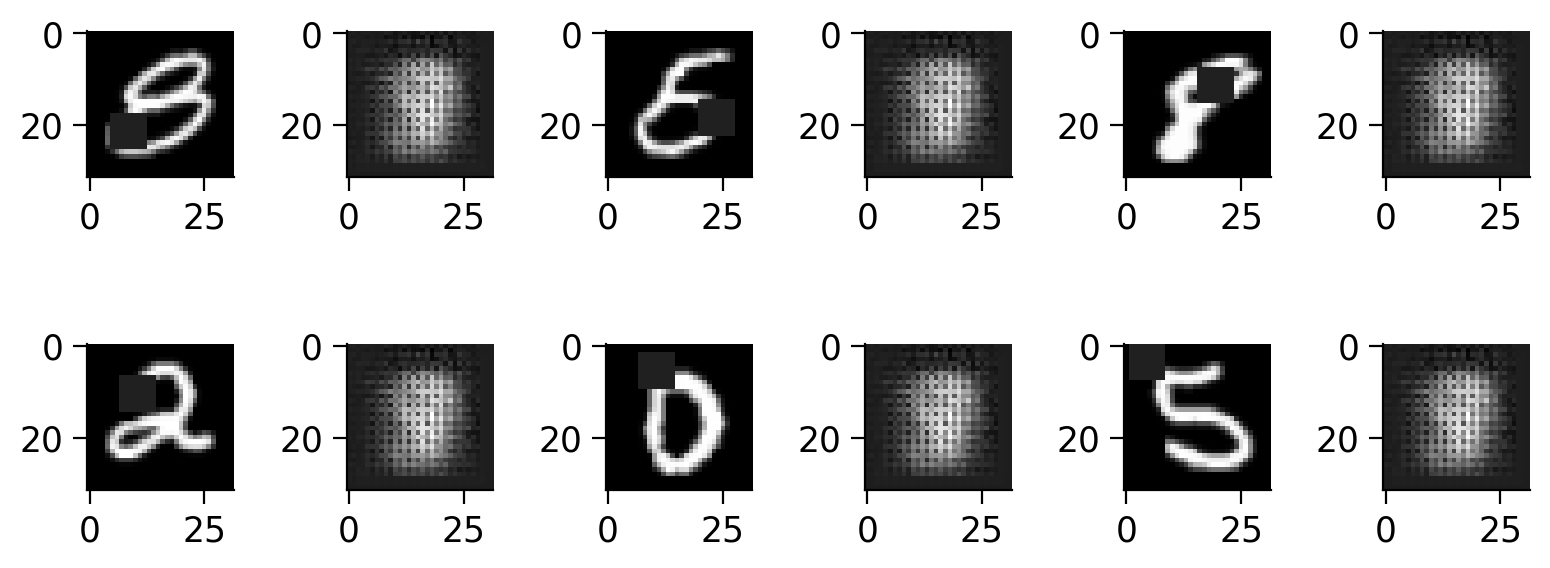

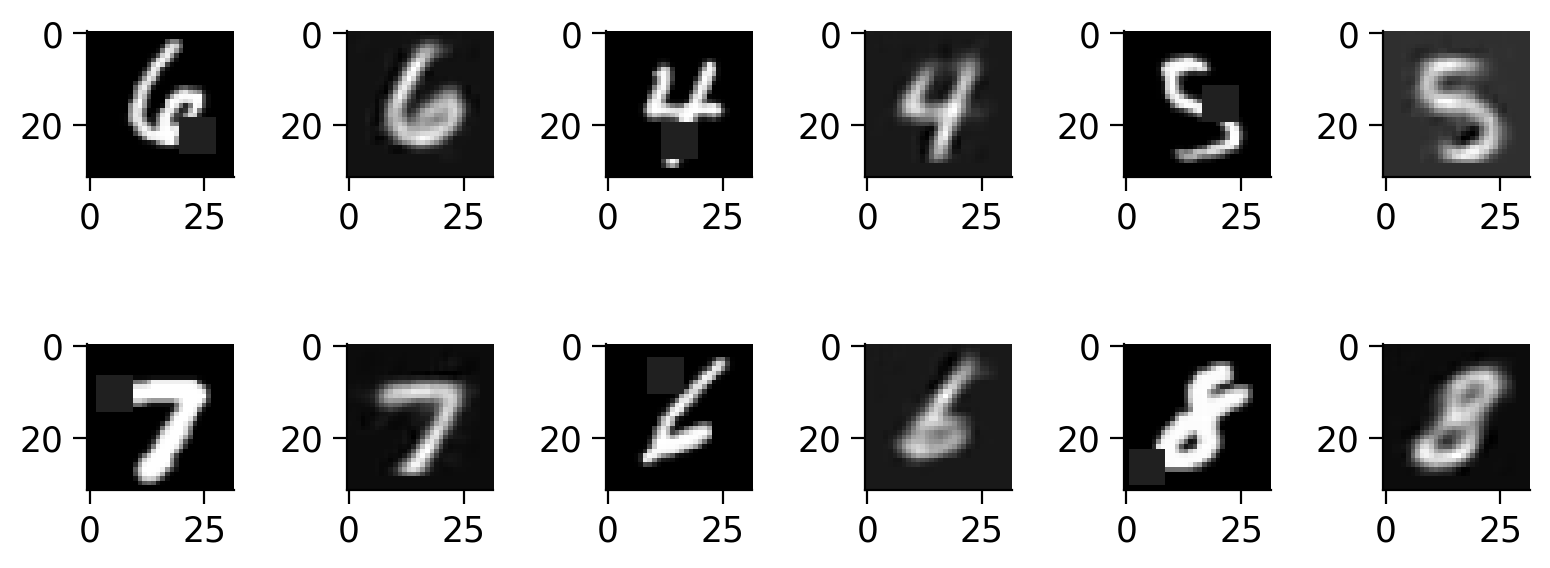
Discussion point 4#
Plot the performance of the model on the test dataset for each network across epochs. What’s the relationship between sample size and number of training epochs?
How do these compare with the other examples above?
# Create a single plot for all test costs with a logarithmic scale
with plt.xkcd():
plt.figure(figsize=(8, 6)) # Set the figure size
for i, n in enumerate(training_points):
epochs = my_epoch_Inpainting[i]
test_cost = my_test_cost_Inpainting[i]
plt.plot(epochs, test_cost, marker='o', linestyle='-', label=f'{n} training points')
plt.xlabel('Epochs')
plt.ylabel('Test cost (log scale)')
plt.title('Test cost over epochs for different training points (inpainting)')
plt.yscale('log')
plt.legend()
plt.grid(True)
plt.show()
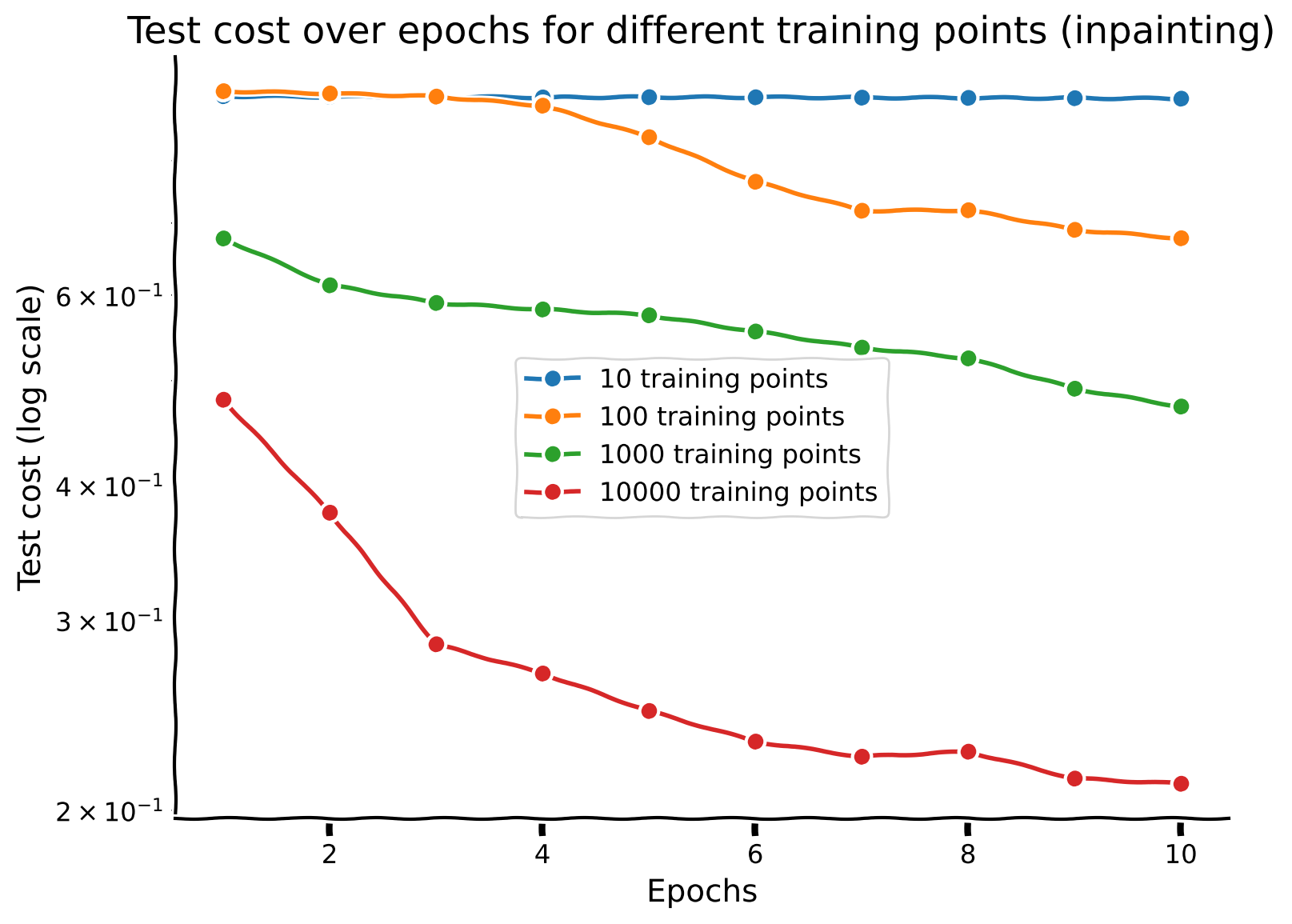
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Discussion_Point_5")
Section 2: Generalization of representations#
In the first part of this tutorial, we focused on training the same backbone architecture (a CNN) on different tasks, measuring how fast these networks learned in terms of training samples and training epochs. Here, we shift our attention to how well these representations generalize across the different tasks. To make this idea more concrete, think of a model that has learned to identify objects in images. Its early layers will be sensitive to basic blocks and lines, orientations, colors etc. The later layers in the model make use of these more basic shapes and gradually build up more complex patterns. Now, if the task changes to estimating the size of objects found in images, then the representations in those early layers (which capture basic shape information) are very useful to this new task, though some of the later layers will need to be tuned to better carry out the task. This is what we mean when we talk about generalizable representations - what learned patterns are useful for multiple (general) tasks - versus representations that are only uniquely relevant for other tasks.
Section 2.1: Transfer#
Taskonomy#
Humans can perform a wide range of tasks. The representations within this system must be general enough to handle multiple tasks, yet specific enough to accommodate differing requirements. We assess the ability of the representations we have learned to perform different tasks by testing generalization from one model to another.
Transfer learning#
We’ll measure the ability of a model’s representations learned for one task by its ability to transfer to other tasks. For each of the four tasks, we’ll use the network trained for the highest number of training points (largest dataset size) and epochs. We define the source task to be the task the model was already trained on and the destination task to be the one we want to compare via transfer learning. A new test set will be provided for each task. To test generalization, we follow these steps:
Create a new network for the destination task using the same architecture as in part 1.
Copy the weights for the first N layers from the source network.
Freeze these copied weights so they do not change during training.
Train the remaining layers on the destination network.
After training, we’ll compare the new performance to the original performance to assess transfer performance (generalization) between each pair of networks.
Because we have N=4 different models, we could measure \(2*(N-1)*(N-2)=12\) transfer directions. In the interest of time, we’ll concentrate on measuring 3 transfer performances from the last 3 models to the classification model.
Copy weights#
We start by defining a function to copy the weights and freeze the layers from the source model to the destination model.
def copy_and_freeze_layers(source_model, destination_model, N):
"""
Copies the weights of the first N layers from the source model to the
destination model and freezes them.
Parameters:
- source_model: The model from which weights are copied.
- destination_model: The model to which weights are copied and trained.
- N: The number of layers to transfer and freeze.
Note: This function assumes the first N layers are directly accessible and
does not handle nested modules automatically.
"""
# Ensure both models are in the same mode (train/eval).
source_model.eval()
destination_model.train()
# Counter to track the number of transferred layers
transferred_layers = 0
source_dict = source_model.state_dict()
dest_dict = destination_model.state_dict()
# Variables to map between layers
source_prefix = list(source_dict.keys())[0]
source_prefix = source_prefix[:source_prefix.find('.')]
source_dict_names = [s[s.find('.')+1:] for s in list(source_dict.keys())]
dest_prefix = list(dest_dict.keys())[0]
dest_prefix = dest_prefix[:dest_prefix.find('.')]
dest_dict_names = [s[s.find('.')+1:] for s in list(dest_dict.keys())]
print(dest_dict_names)
# Transfer layers by matching keys
for name in source_dict_names:
if name in dest_dict_names and transferred_layers < N:
try:
dest_dict[dest_prefix+'.'+name].copy_(source_dict[source_prefix+'.'+name])
transferred_layers += 1
print(f"Copied {name}")
except Exception as e:
print(f"Could not copy {name}: {e}")
# Load the updated state dictionary back to the destination model
destination_model.load_state_dict(dest_dict)
print(transferred_layers)
# Freeze the transferred layers
for name, param in destination_model.named_parameters():
if name[name.find('.')+1:] in source_dict_names and transferred_layers > 0:
print('froze ',name)
param.requires_grad = False
transferred_layers -= 1
print(f"Copied and froze {N} layers.")
Transfer example 1: regression to classification#
We first copy the weights from a regression network to a classification network and freeze them.
MODEL_NAME_SOURCE = "models/ConvNet_regression_10000_epoch_10.pth"
model_source = RegressionConvNet(ConvNeuralNet(), RegressionOutputLayer())
# Load the checkpoint
checkpoint = torch.load(MODEL_NAME_SOURCE)
# Extract the state dictionary from the checkpoint
model_state_dict = checkpoint['model_state_dict']
# Load the state dictionary into the model
model_source.load_state_dict(model_state_dict)
# Define the destination model
model_destination = ClassificationConvNet(ConvNeuralNet(), ClassificationOutputLayer())
# Number of layers to transfer and freeze
N = 8
# Transfer and freeze layers
copy_and_freeze_layers(model_source, model_destination, N)
['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias', 'fc.weight', 'fc.bias']
Copied conv1.weight
Copied conv1.bias
Copied conv2.weight
Copied conv2.bias
Copied fc1.weight
Copied fc1.bias
Copied fc2.weight
Copied fc2.bias
8
froze ConvNet.conv1.weight
froze ConvNet.conv1.bias
froze ConvNet.conv2.weight
froze ConvNet.conv2.bias
froze ConvNet.fc1.weight
froze ConvNet.fc1.bias
froze ConvNet.fc2.weight
froze ConvNet.fc2.bias
Copied and froze 8 layers.
Training#
We train the destination network on the classification task with the transferred weights.
set_seed(42)
batch_size = 64 # Define your batch size
test_loader_transfer = torch.utils.data.DataLoader(dataset = test_dataset_transfer,
batch_size = batch_size,
shuffle = True)
sampled_train_loader, sampled_val_loader = get_random_sample_train_val(train_dataset, val_dataset, batch_size, N_train_data)
# Optimizer
optimizer = optim.Adam(params=model_destination.parameters(), lr=0.001)
# Training parameters
N_train_data = 10000
task_name = "regression_classification"
epochs_max = 10 # Number of epochs
acc_flag = False # Whether to calculate accuracy
triplet_flag = False # Whether to use triplet loss
# Call the train_transfer function
my_epoch_transfer1, my_train_cost_transfer1, my_val_cost_transfer1, my_test_cost_transfer1 = train_transfer(
model_destination,
sampled_train_loader,
sampled_val_loader,
test_loader_transfer,
cost_classification,
optimizer,
epochs_max,
acc_flag,
triplet_flag,
task_name,
N_train_data
)
Epoch: 1| Train cost: 2.30229| Val cost: 2.30211| Test cost: 2.30199|
Saving the model: models/ConvNet_regression_classification_10000_epoch_1.pth
Epoch: 2| Train cost: 2.30187| Val cost: 2.30188| Test cost: 2.30149|
Saving the model: models/ConvNet_regression_classification_10000_epoch_2.pth
Epoch: 3| Train cost: 2.30146| Val cost: 2.30165| Test cost: 2.30109|
Saving the model: models/ConvNet_regression_classification_10000_epoch_3.pth
Epoch: 4| Train cost: 2.30102| Val cost: 2.30138| Test cost: 2.30061|
Saving the model: models/ConvNet_regression_classification_10000_epoch_4.pth
Epoch: 5| Train cost: 2.30045| Val cost: 2.30101| Test cost: 2.29985|
Saving the model: models/ConvNet_regression_classification_10000_epoch_5.pth
Epoch: 6| Train cost: 2.30005| Val cost: 2.30059| Test cost: 2.29962|
Saving the model: models/ConvNet_regression_classification_10000_epoch_6.pth
Epoch: 7| Train cost: 2.29954| Val cost: 2.29975| Test cost: 2.29884|
Saving the model: models/ConvNet_regression_classification_10000_epoch_7.pth
Epoch: 8| Train cost: 2.29901| Val cost: 2.30042| Test cost: 2.29814|
Saving the model: models/ConvNet_regression_classification_10000_epoch_8.pth
Epoch: 9| Train cost: 2.29859| Val cost: 2.29936| Test cost: 2.29805|
Saving the model: models/ConvNet_regression_classification_10000_epoch_9.pth
Epoch: 10| Train cost: 2.29814| Val cost: 2.29870| Test cost: 2.29756|
Saving the model: models/ConvNet_regression_classification_10000_epoch_10.pth
Elapsed: 35.651625871658325
We compare the performance of the transferred model with the original network.
# Create a single plot for all training costs with a logarithmic scale
with plt.xkcd():
plt.figure(figsize=(8, 6)) # Set the figure size
epochs = my_epoch_Classification[-1]
epochs_transfer_1 = my_epoch_transfer1
test_cost = my_test_cost_Classification[-1]
test_cost_1 = my_test_cost_transfer1
# Plot the autoencoder training cost
plt.plot(epochs, test_cost, marker='o', linestyle='-', label='Original Classifier (10000 training points)')
# Plot the classification_autoencoder training cost
plt.plot(epochs_transfer_1, test_cost_1, marker='x', linestyle='-', label='Regression to Classification (10000 training points)')
# Set the labels and title
plt.xlabel('Epochs')
plt.ylabel('Test cost (log scale)')
plt.title('Test cost over epochs')
plt.yscale('log') # Set the y-axis to a logarithmic scale
# Add the legend and grid
plt.legend()
plt.grid(True)
# Show the plot
plt.show()
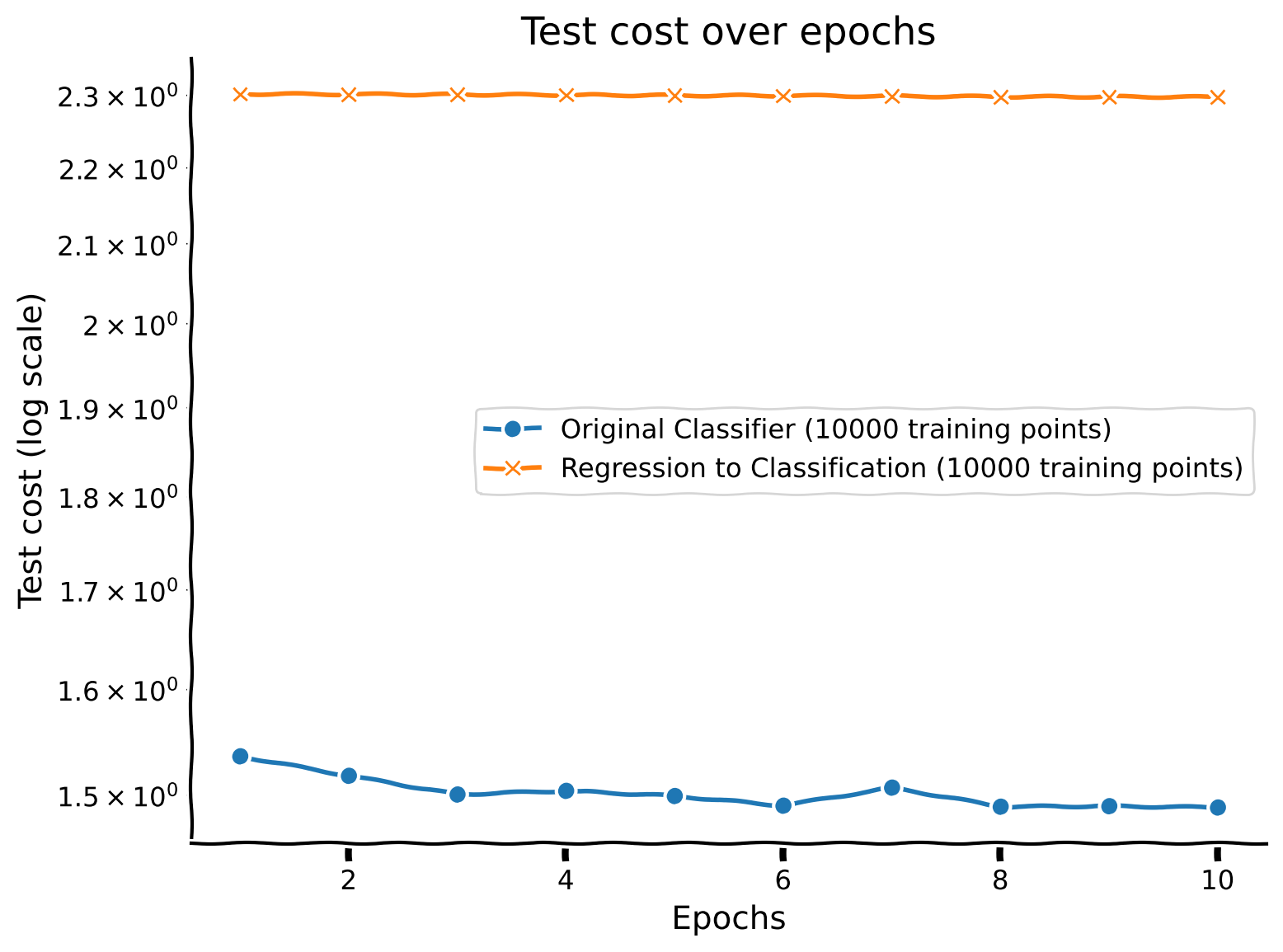
Discussion point 5#
What did the regression model learn? What does its performance on the classification task after fine-tuning indicate?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Discussion_Point_5")
Transfer example 2: autoencoder to classification#
Now we do the same, but we transfer the weights of the network to predict the total number of “ON” pixels to the autoencoder task. How well do you think this will work? Think about the necessary features required to solve the task and consider if there could be much overlap. There is no clear answer to this question, but thinking about it will be useful.
MODEL_NAME_SOURCE = "models/ConvNet_autoencoder_10000_epoch_10.pth"
model_source = Autoencoder(ConvNeuralNet(), BottleneckLayer(M), ConvNeuralNetDecoder(M))
# Load the checkpoint
checkpoint = torch.load(MODEL_NAME_SOURCE)
# Extract the state dictionary from the checkpoint
model_state_dict = checkpoint['model_state_dict']
# Load the state dictionary into the model
model_source.load_state_dict(model_state_dict)
# Define the destination model
model_destination = ClassificationConvNet(ConvNeuralNet(), ClassificationOutputLayer())
# Number of layers to transfer and freeze
N = 8
# Transfer and freeze layers
copy_and_freeze_layers(model_source, model_destination, N)
['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias', 'fc.weight', 'fc.bias']
Copied conv1.weight
Copied conv1.bias
Copied conv2.weight
Copied conv2.bias
Copied fc1.weight
Copied fc1.bias
Copied fc2.weight
Copied fc2.bias
8
froze ConvNet.conv1.weight
froze ConvNet.conv1.bias
froze ConvNet.conv2.weight
froze ConvNet.conv2.bias
froze ConvNet.fc1.weight
froze ConvNet.fc1.bias
froze ConvNet.fc2.weight
froze ConvNet.fc2.bias
Copied and froze 8 layers.
set_seed(42)
batch_size = 64 # Define your batch size
test_loader_transfer = DataLoader(dataset = test_dataset_transfer,
batch_size = batch_size,
shuffle = True)
sampled_train_loader, sampled_val_loader = get_random_sample_train_val(train_dataset, val_dataset, batch_size, N_train_data)
# Optimizer
optimizer = optim.Adam(params=model_destination.parameters(), lr=0.001)
# Training parameters
N_train_data = 10000
task_name = "autoencoder_classification"
epochs_max = 10 # Number of epochs
acc_flag = False # Whether to calculate accuracy
triplet_flag = False # Whether to use triplet loss
# Call the train_transfer function
my_epoch_transfer2, my_train_cost_transfer2, my_val_cost_transfer2, my_test_cost_transfer2 = train_transfer(
model_destination,
sampled_train_loader,
sampled_val_loader,
test_loader_transfer,
cost_classification,
optimizer,
epochs_max,
acc_flag,
triplet_flag,
task_name,
N_train_data
)
Epoch: 1| Train cost: 2.11301| Val cost: 2.06528| Test cost: 2.05310|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_1.pth
Epoch: 2| Train cost: 2.06735| Val cost: 2.05482| Test cost: 2.04824|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_2.pth
Epoch: 3| Train cost: 2.01539| Val cost: 1.99300| Test cost: 1.96829|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_3.pth
Epoch: 4| Train cost: 1.98055| Val cost: 1.99027| Test cost: 1.97140|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_4.pth
Epoch: 5| Train cost: 1.97799| Val cost: 1.98077| Test cost: 1.96582|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_5.pth
Epoch: 6| Train cost: 1.97830| Val cost: 1.98092| Test cost: 1.96194|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_6.pth
Epoch: 7| Train cost: 1.97619| Val cost: 1.97761| Test cost: 1.96093|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_7.pth
Epoch: 8| Train cost: 1.97587| Val cost: 1.97696| Test cost: 1.96575|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_8.pth
Epoch: 9| Train cost: 1.97350| Val cost: 1.98023| Test cost: 1.96468|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_9.pth
Epoch: 10| Train cost: 1.97369| Val cost: 1.97199| Test cost: 1.96318|
Saving the model: models/ConvNet_autoencoder_classification_10000_epoch_10.pth
Elapsed: 36.04919958114624
We compare the performance of the transferred model with the original network.
# Create a single plot for all training costs with a logarithmic scale
with plt.xkcd():
plt.figure(figsize=(8, 6)) # Set the figure size
epochs = my_epoch_Classification[-1]
epochs_transfer_1 = my_epoch_transfer1
epochs_transfer_2 = my_epoch_transfer2
test_cost = my_test_cost_Classification[-1]
test_cost_1 = my_test_cost_transfer1
test_cost_2 = my_test_cost_transfer2
# Plot the autoencoder training cost
plt.plot(epochs, test_cost, marker='o', linestyle='-', label='Original Classifier (10000 training points)')
# Plot the classification_autoencoder training cost
plt.plot(epochs_transfer_1, test_cost_1, marker='x', linestyle='-', label='Regression to Classification (10000 training points)')
# Plot the classification_autoencoder training cost
plt.plot(epochs_transfer_2, test_cost_2, marker='x', linestyle='-', label='Autoencoder to Classification (10000 training points)')
# Set the labels and title
plt.xlabel('Epochs')
plt.ylabel('Test cost (log scale)')
plt.title('Test cost over epochs')
plt.yscale('log') # Set the y-axis to a logarithmic scale
# Add the legend and grid
plt.legend()
plt.grid(True)
# Show the plot
plt.show()
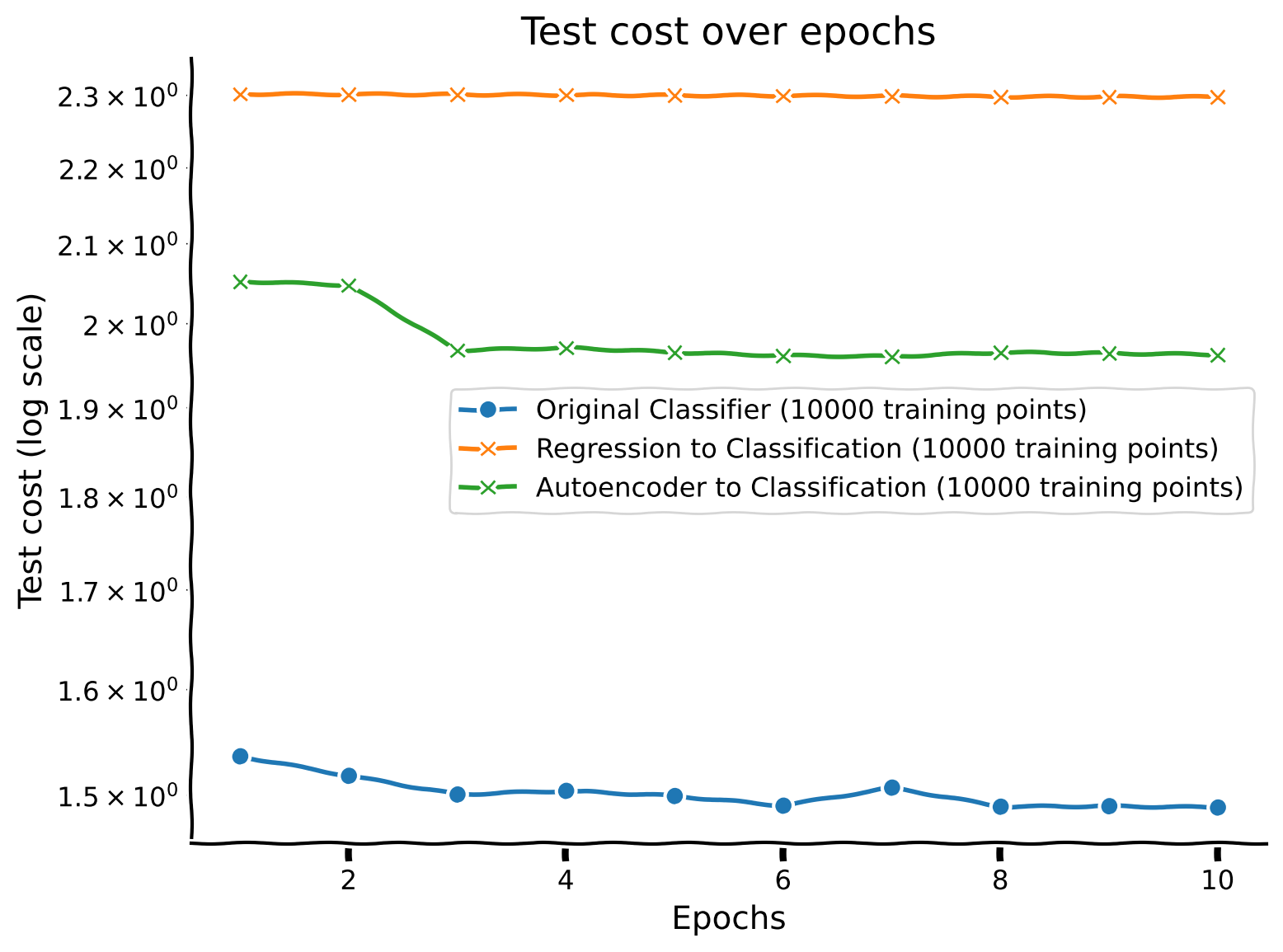
Discussion point 6#
How well does the representation learned on the autoencoder transfer to classification?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Discussion_Point_6")
Transfer example 3: inpainting to classification#
Finally, we’ll transfer the weights of the inpainting network to the classification network. How well do you think this will work? Again, consider the breakdown of the features that would need to support both tasks. Is there an overlap?
MODEL_NAME_SOURCE = "models/ConvNet_inpainting_10000_epoch_10.pth"
M = 16
model_source = Autoencoder(ConvNeuralNet(), BottleneckLayer(M), ConvNeuralNetDecoder(M))
# Load the checkpoint
checkpoint = torch.load(MODEL_NAME_SOURCE)
# Extract the state dictionary from the checkpoint
model_state_dict = checkpoint['model_state_dict']
# Load the state dictionary into the model
model_source.load_state_dict(model_state_dict)
# Define the destination model
model_destination = ClassificationConvNet(ConvNeuralNet(), ClassificationOutputLayer())
# Number of layers to transfer and freeze
N = 8
# Transfer and freeze layers
copy_and_freeze_layers(model_source, model_destination, N)
['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'fc1.weight', 'fc1.bias', 'fc2.weight', 'fc2.bias', 'fc.weight', 'fc.bias']
Copied conv1.weight
Copied conv1.bias
Copied conv2.weight
Copied conv2.bias
Copied fc1.weight
Copied fc1.bias
Copied fc2.weight
Copied fc2.bias
8
froze ConvNet.conv1.weight
froze ConvNet.conv1.bias
froze ConvNet.conv2.weight
froze ConvNet.conv2.bias
froze ConvNet.fc1.weight
froze ConvNet.fc1.bias
froze ConvNet.fc2.weight
froze ConvNet.fc2.bias
Copied and froze 8 layers.
set_seed(42)
batch_size = 64 # Define your batch size
test_loader_transfer = torch.utils.data.DataLoader(dataset = test_dataset_transfer,
batch_size = batch_size,
shuffle = True)
sampled_train_loader, sampled_val_loader = get_random_sample_train_val(train_dataset, val_dataset, batch_size, N_train_data)
# Optimizer
optimizer = optim.Adam(params=model_destination.parameters(), lr=0.001)
# Training parameters
N_train_data = 10000
task_name = "inpainting_classification"
epochs_max = 10 # Number of epochs
acc_flag = False # Whether to calculate accuracy
triplet_flag = False # Whether to use triplet loss
# Call the train_transfer function
my_epoch_transfer3, my_train_cost_transfer3, my_val_cost_transfer3, my_test_cost_transfer3 = train_transfer(
model_destination,
sampled_train_loader,
sampled_val_loader,
test_loader_transfer,
cost_classification,
optimizer,
epochs_max,
acc_flag,
triplet_flag,
task_name,
N_train_data
)
Epoch: 1| Train cost: 2.08974| Val cost: 2.01776| Test cost: 1.99194|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_1.pth
Epoch: 2| Train cost: 2.00194| Val cost: 1.99326| Test cost: 1.97184|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_2.pth
Epoch: 3| Train cost: 1.99250| Val cost: 1.99701| Test cost: 1.96457|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_3.pth
Epoch: 4| Train cost: 1.98851| Val cost: 1.99065| Test cost: 1.96949|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_4.pth
Epoch: 5| Train cost: 1.98501| Val cost: 1.98452| Test cost: 1.96313|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_5.pth
Epoch: 6| Train cost: 1.98496| Val cost: 1.98256| Test cost: 1.96016|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_6.pth
Epoch: 7| Train cost: 1.98236| Val cost: 1.98380| Test cost: 1.96117|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_7.pth
Epoch: 8| Train cost: 1.96874| Val cost: 1.91986| Test cost: 1.89770|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_8.pth
Epoch: 9| Train cost: 1.90781| Val cost: 1.89947| Test cost: 1.88844|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_9.pth
Epoch: 10| Train cost: 1.90122| Val cost: 1.89825| Test cost: 1.88662|
Saving the model: models/ConvNet_inpainting_classification_10000_epoch_10.pth
Elapsed: 36.43200349807739
# Create a single plot for all training costs with a logarithmic scale
with plt.xkcd():
plt.figure(figsize=(8, 6)) # Set the figure size
epochs = my_epoch_Classification[-1]
epochs_transfer_1 = my_epoch_transfer1
epochs_transfer_2 = my_epoch_transfer2
epochs_transfer_3 = my_epoch_transfer3
test_cost = my_test_cost_Classification[-1]
test_cost_1 = my_test_cost_transfer1
test_cost_2 = my_test_cost_transfer2
test_cost_3 = my_test_cost_transfer3
plt.plot(epochs, test_cost, marker='o', linestyle='-', label='Original Classifier (10000 training points)')
plt.plot(epochs_transfer_1, test_cost_1, marker='x', linestyle='-', label='Regression to Classification (10000 training points)')
plt.plot(epochs_transfer_2, test_cost_2, marker='x', linestyle='-', label='Autoencoder to Classification (10000 training points)')
plt.plot(epochs_transfer_3, test_cost_3, marker='x', linestyle='-', label='Inpainting to Classification (10000 training points)')
# Set the labels and title
plt.xlabel('Epochs')
plt.ylabel('Test cost (log scale)')
plt.title('Test cost over epochs')
plt.yscale('log') # Set the y-axis to a logarithmic scale
# Add the legend and grid
plt.legend()
plt.grid(True)
# Show the plot
plt.show()
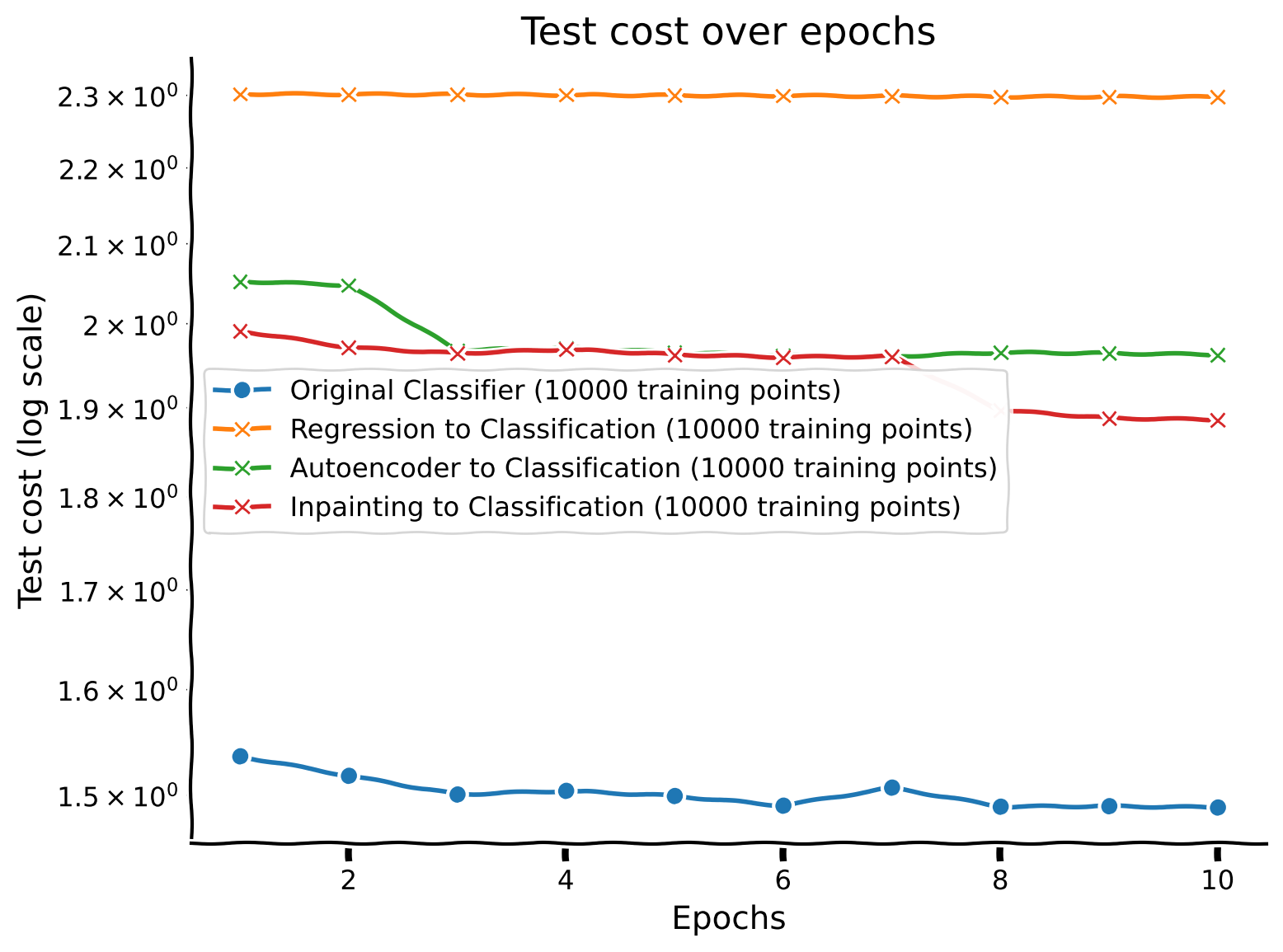
Discussion point 7#
Consider the test loss across these three networks (regression, autoencoder, inpainting). What does this test loss tell us about the representations learned by these networks?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Discussion_Point_7")
Bonus discussion point 8#
How would you find out if the representations learned by the networks are similar or different, apart from their performance on downstream tasks?
Submit your feedback#
Show code cell source
# @title Submit your feedback
content_review(f"{feedback_prefix}_Discussion_Point_8")
The Big Picture#
In this tutorial, we explored the concept of generalization of representation in AI, namely the concept of representational transfer. We trained networks on several distinct tasks including classification, regression, autoencoding, and inpainting. We showed how the specification of different cost functions on the output layers can make a network perform a completely different task. We specified multiple different cost functions that were each associated with defining one of the tasks outlined earler.
We explored how a network trained on one task might transfer to another task / network. We found that richer tasks, including inpainting and autoencoding, lead to more useful representations for downstream tasks like classification. These tasks involve needing to capture multiple pieces of information across local and global contexts, big picture features as well as smaller details.
Humans are great at generalization and we have limited neural networks that are re-used across many different tasks. Is this an idea we can take forward to creating better AI models?